ZFS RAID is not like traditional RAID. Its on-disk structure is far more complex than that of a traditional RAID implementation. This complexity is driven by the wide array of data protection features ZFS offers. Because its on-disk structure is so complex, predicting how much usable capacity you'll get from a set of hard disks given a vdev layout is surprisingly difficult. There are layers of overhead that need to be understood and accounted for to get a reasonably accurate estimate. I've found that the best way to get my head wrapped around ZFS allocation overhead is to step through an example.
We'll start by picking a less-than-ideal RAIDZ vdev layout so we can see the impact of all the various forms of ZFS overhead. Once we understand RAIDZ, understanding mirrored and striped vdevs will be simple. The process for calculating dRAID capacity adds a bit of complexity, but we'll cover that below.
This example will use 14x 18TB drives in two 7-wide RAIDZ2 (7wZ2) vdevs. It will generally be easier for us to work in bytes so we don't have to worry about conversion between TB and TiB.
Starting with the capacity of the individual drives, we'll subtract the size of the swap partition. The swap partition acts as an extension of the system's physical memory pool. If a running process needs more memory than is currently available, the system can unload some of its in-memory data onto the swap space. By default, TrueNAS CORE creates a 2GiB swap partition on every disk in the data pool. Other distributions may create a large or smaller swap partition or might not create one at all.
$$ 18 \times 1{,}000^4 - 2 \times 1{,}024^3 = 17{,}997{,}852{,}516{,}352 \text{ bytes} $$Next, we want to account for reserved sectors at the start of the disk. The layout and size of these reserved sectors will depend on your operating system and partition scheme, but we'll use FreeBSD and GPT for this example because that is what's used by TrueNAS CORE and Enterprise. We can check sector alignment by running
root@truenas[~]# gpart list da1
Geom name: da1
modified: false
state: OK
fwheads: 255
fwsectors: 63
last: 35156249959
first: 40
entries: 128
scheme: GPT
Providers:
1. Name: da1p1
Mediasize: 2147483648 (2.0G)
Sectorsize: 512
Stripesize: 0
Stripeoffset: 65536
Mode: r0w0e0
efimedia: HD(1,GPT,b1c0188e-b098-11ec-89c7-0800275344ce,0x80,0x400000)
rawuuid: b1c0188e-b098-11ec-89c7-0800275344ce
rawtype: 516e7cb5-6ecf-11d6-8ff8-00022d09712b
label: (null)
length: 2147483648
offset: 65536
type: freebsd-swap
index: 1
end: 4194431
start: 128
2. Name: da1p2
Mediasize: 17997852430336 (16T)
Sectorsize: 512
Stripesize: 0
Stripeoffset: 2147549184
Mode: r1w1e2
efimedia: HD(2,GPT,b215c5ef-b098-11ec-89c7-0800275344ce,0x400080,0x82f39cce8)
rawuuid: b215c5ef-b098-11ec-89c7-0800275344ce
rawtype: 516e7cba-6ecf-11d6-8ff8-00022d09712b
label: (null)
length: 17997852430336
offset: 2147549184
type: freebsd-zfs
index: 2
end: 35156249959
start: 4194432
Consumers:
1. Name: da1
Mediasize: 18000000000000 (16T)
Sectorsize: 512
Mode: r1w1e3
We'll first note that the sector size used on this drive is 512 bytes. Also note that the first logical block on this disk is actually sector 40; that means we're losing \(40 \times 512 = 20{,}480 \text{ bytes}\) right there.
The
Before ZFS does anything with this partition, it rounds its size down to align with a 256KiB block. This rounded-down size is referred to as the
Inside the physical ZFS volume, we need to account for the special labels added to each disk. ZFS creates 4 copies of a 256KiB vdev label on each disk (2 at the start of the ZFS partition and 2 at the end) plus a 3.5MiB embedded boot loader region. Details on the function of the vdev labels can be found here and details on how the labels are sized and arranged can be found here and in the sections just below this (lines 541 and 548). We subtract this 4.5MiB (\(4 \times 256 \text{KiB} + 3.5 \text{MiB}\)) of space from the ZFS partition to get its "usable" size:
$$ 17{,}997{,}852{,}311{,}552 - 4 \times 262{,}144 - 3{,}670{,}016 = 17{,}997{,}847{,}592{,}960 \text{ bytes} $$Next up, we need to calculate the allocation size or "
That's about 114.58 TiB. ZFS takes this chunk of storage represented by the allocation size and breaks it until smaller, uniformly-sized buckets called "metaslabs". ZFS creates these metaslabs because they're much more manageable than the full vdev size when tracking used and available space via spacemaps. The size of the metaslabs are primarily controlled by the metaslab shift or "
ZFS sets
On the other hand, the "cutoff" for going from
Once we have the value of
With
This gives us 7,333 metaslabs per vdevs. We can check our progress so far on an actual ZFS system by using the zdb command provided by ZFS. We can check vdev asize and the metaslab shift value by running
root@truenas[~]# zdb -U /data/zfs/zpool.cache -C tank
MOS Configuration:
version: 5000
name: 'tank'
state: 0
txg: 11
pool_guid: 7584042259335681111
errata: 0
hostid: 3601001416
hostname: ''
com.delphix:has_per_vdev_zaps
vdev_children: 2
vdev_tree:
type: 'root'
id: 0
guid: 7584042259335681111
create_txg: 4
children[0]:
type: 'raidz'
id: 0
guid: 2993118147866813004
nparity: 2
metaslab_array: 268
metaslab_shift: 34
ashift: 12
asize: 125984933150720
is_log: 0
create_txg: 4
com.delphix:vdev_zap_top: 129
children[0]:
type: 'disk'
... (output truncated) ...
root@truenas[~]# zdb -U /data/zfs/zpool.cache -m tank
Metaslabs:
vdev 0 ms_unflushed_phys object 270
metaslabs 7333 offset spacemap free
--------------- ------------------- --------------- ------------
metaslab 0 offset 0 spacemap 274 free 16.0G
space map object 274:
smp_length = 0x18
smp_alloc = 0x12000
Flush data:
unflushed txg=5
metaslab 1 offset 400000000 spacemap 273 free 16.0G
space map object 273:
smp_length = 0x18
smp_alloc = 0x21000
Flush data:
unflushed txg=6
... (output truncated) ...
To calculate useful space in our vdev, we multiply the metaslab size by the metaslab count. This means that space within the ZFS partition but not covered by one of the metaslabs isn't useful to us and is effectively lost. In theory, by using a smaller
That's about 114.58 TiB of useful space per vdev. If we multiply that by the quantity of vdevs, we get the ZFS pool size:
$$ 125{,}979{,}980{,}726{,}272 \times 2 = 251{,}959{,}961{,}452{,}544 \text{ bytes} $$We can confirm this by running
root@truenas[~]# zpool list -p -o name,size,alloc,free tank
NAME SIZE ALLOC FREE
tank 251959961452544 1437696 251959960014848
The
Note that the zpool SIZE value matches what we calculated above. We're going to set this number aside for now and calculate RAIDZ parity and padding. Before we proceed, it will be helpful to review a few ZFS basics including
Hard disks and SSDs divide their space into tiny logical storage buckets called "sectors". A sector is usually 4KiB but could be 512 bytes on older hard drives or 8KiB on some SSDs. A sector represents the smallest read or write a disk can do in a single operation. ZFS tracks disks' sector size as the "
In RAIDZ, the smallest useful write we can make is \(p+1\) sectors wide where \(p\) is the parity level (1 for RAIDZ1, 2 for Z2, 3 for Z3). This gives us a single sector of user data and however many parity sectors we need to protect that user data. With this in mind, ZFS allocates space on RAIDZ vdevs in even multiples of this \(p+1\) value. It does this so we don't end up with unusable-small gaps on the disk. For example, imagine we made a 5-sector write to a RAIDZ2 vdev (3 user data sectors and 2 parity sectors). We later delete that data and are left with a 5-sector gap on the disk. We now make a 3-sector write to the Z2 vdev, it lands in that 5-sector gap and we're left with a 2-sector gap that we can't do anything with. That space can't be recovered without totally rewriting every other sector on the disk after it.
To avoid this, ZFS will pad out all writes to RAIDZ vdevs so they're an even multiple of this \(p+1\) value. By "pad out" we mean it just logically includes these extra few sectors in the block to be written but doesn't actually write anything to them. The ZFS source code refers to them as "skip" sectors.
Unlike traditional RAID5 and RAID6 implementations, ZFS supports partial-stripe writes. This has a number of important advantages but also presents some implications for space calculation that we'll need to consider. Supporting partial stripe writes means that in our 7wZ2 vdev example, we can support a write of 12 total sectors even though 12 is not an even multiple of our stripe width (7). 12 is evenly divisible by \(p+1\) (3 in this case), so we don't even need any padding. We would have a single full stripe of 7 sectors (2 parity sectors plus 5 data sectors) followed by a partial stripe with 2 parity sectors and 3 data sectors. This will be important because even though we can support partial stripe writes, every stripe (including those partial stripes) need a full set of p parity sectors.
The last ZFS concept we need to understand here is the
You can read more about ZFS' handling of partial stripe writes and block padding in this article by Matt Ahrens.
Getting back to our capacity example, we have the minimum sector count already calculated above at \(p+1 = 3\). Next, we need to figure out how many sectors will get filled up by a
Our stripe width is 7 disks, so we can figure out how many stripes this 128KiB write will take. Remember, we need 2 parity sectors per stripe, so we divide the 32 sectors by 5 because that's the number of data sectors per stripe:
$$ \frac{32}{7-2} = 6.4 $$We can visualize how this might look on the disks (P represents a parity sectors, D represents a data sectors):
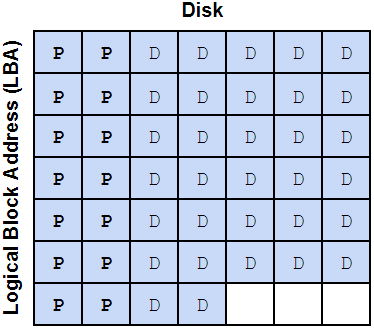
As mentioned above, that partial 0.4 stripe also gets 2 parity sectors, so we have 7 stripes of parity data at 2 parity sectors per stripe, or 14 total parity sectors. We now have 32 data sectors, 14 parity sectors, adding those, we get 46 total sectors for this data block. 46 is not an even multiple of our minimum sector count (3), so we need to add 2 padding sectors. This brings our total sector count to 48: 32 data sectors, 14 parity sectors, and 2 padding sectors.
With the padding sectors included, this is what the full 128KiB block might look like on disk. I've drawn two blocks so you can see how alignment of the second block gets shifted a bit to accommodate the partial stripe we've written. The X's represent the padding sectors.
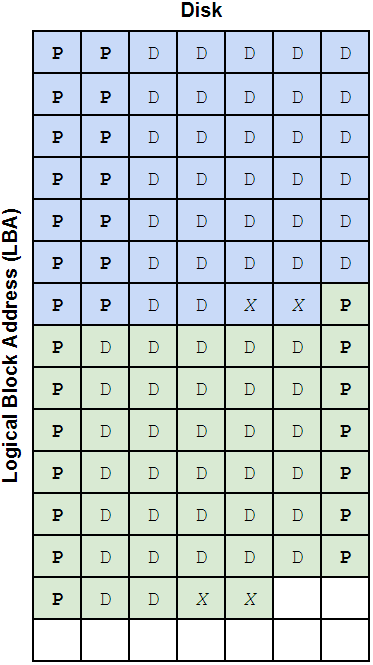
This probably looks kind of weird because we have one parity sector at the start of the second block just hanging out by itself, but even though it's not on the same exact row as the data it's protecting, it's still providing that protection. ZFS knows where that parity data is written so it doesn't really matter what LBA it gets written to, as long as it's on the correct disk.
We can calculate a data storage efficiency ratio by dividing our 32 data sectors by the 48 total sectors it takes to store them on disk with this particular vdev layout.
$$ \frac{32}{48} = 0.66667 $$ZFS uses something similar to this ratio when allocating space but in order to simplify calculations and avoid multiplication overflows and other weird stuff it tracks this ratio as a fraction of 512. In other words, to more accurately represent how ZFS "sees" the on-disk space, we need to convert the 32/48 fraction to the nearest fraction of 512. We'll need to round down to get a whole number in the numerator (the top part of the fraction). To do this, we calculate:
$$ \frac{\lfloor 0.66667 \times 512 \rfloor}{512} = 0.666015625 = \frac{341}{512} $$This 341/512 fraction is called the
The last thing we need to account for is SPA slop space. ZFS reserves the last little bit of pool capacity "to ensure the pool doesn't run completely out of space due to unaccounted changes (e.g. to the MOS)". Normally this is 1/32 of the usable pool capacity with a minimum value of 128MiB. OpenZFS 2.0.7 also introduced a maximum limit to slop space of 128GiB (this is good; slop space used to be HUGE on large pools). You can read about SPA slop space reservation here.
For our example pool, slop space would be...
$$ 167{,}809{,}271{,}201{,}792 \times \frac{1}{32} = 5{,}244{,}039{,}725{,}056 \text{ bytes} $$That's 4.77 TiB reserved... again, a TON of space. If we're running OpenZFS 2.0.7 or later, we'll use 128 GiB instead:
$$ 167{,}809{,}271{,}201{,}792 - 128 \times 1{,}024^3 = 167{,}671{,}832{,}248{,}320 \text{ bytes} = 156{,}156.5625 \text{ GiB} = 152.4966 \text{ TiB} $$And there we have it! This is the total usable capacity of a pool of 14x 18TB disks configured in 2x 7wZ2. We can confirm the calculations using
root@truenas[~]# zfs list -p tank
NAME USED AVAIL REFER MOUNTPOINT
tank 1080288 167671831168032 196416 /mnt/tank
As with the
Mirrored vdevs work in a similar way but the vdev
dRAID Capacity Calculation
Capacity calculation for dRAID vdevs is similar to that of RAIDZ but includes a few extra steps. We'll run through an abbreviated example calculation with 2x dRAID2:5d:20c:1s with 8TB disks (no swap space reserved this time).
dRAID still aligns the space on each drive to a 256KiB block size, so we go from 8,000,000,000,000 bytes to 7,999,999,967,232 bytes per 8TB disk:
$$ \left\lfloor \frac{8{,}000{,}000{,}000{,}000}{256 \times 1{,}024} \right\rfloor \times 256 \times 1{,}024 = 7{,}999{,}999{,}967{,}232 \text{ bytes} $$From there, we reserve space for the on-disk ZFS labels (just like in RAIDZ) but we also reserve an extra 32MiB for dRAID reflow space which is used when expanding a dRAID vdev. Details on the reflow reserve space can be found here.
$$ 7{,}999{,}999{,}967{,}232 - (256 \times 1024 \times 4) - (7 \times 2^{19}) - 2^{25} = 7{,}999{,}961{,}694{,}208 \text{ bytes} $$dRAID does not support partial stripe writes so we go through several extra alignment operations to make sure our capacity is an even multiple of the group width. Group width in dRAID is defined as the number of data disks in the configuration plus the number of parity disks. For our configuration, that's \(5 + 2 = 7\) disks. dRAID allocates 16MiB of space from each disk in the group to form a row (details here), so we can multiply the row height (which is always 16 MiB) by the group width (7) to get the group size:
$$ 7 \times 16 \times 1{,}024^2 = 117{,}440{,}512 \text{ bytes} $$First we align the individual disk's allocatable size to the row height (again, always 16 MiB):
$$ \left\lfloor \frac{7{,}999{,}961{,}694{,}208}{16 \times 1{,}024^2} \right\rfloor \times 16 \times 1{,}024^2 = 7{,}999{,}947{,}014{,}144 \text{ bytes} $$To get the total allocatable capacity, we multiply this by the number of child disks minus the number of spare disks in the vdev:
$$ 7{,}999{,}947{,}014{,}144 \times (20 - 1) = 151{,}998{,}993{,}268{,}736 \text{ bytes} $$And then this number is aligned to the group size which we calculated above:
$$ \left\lfloor \frac{151{,}998{,}993{,}268{,}736}{117{,}440{,}512} \right\rfloor \times 117{,}440{,}512 = 151{,}998{,}909{,}382{,}656 \text{ bytes} $$This is the allocatable size (or asize) of each of our two dRAID vdevs. We go through the same logic as RAIDZ used to determine the metaslab count but each metaslab gets its size adjusted so its starting offset and its overall size lines up with the minimum allocation size. The minimum allocation size is the group width times the sector size (or \(2^\text{ashift}\)). For our layout that is:
$$ 7 \times 2^{12} = 28{,}672 \text{ bytes} $$This represents the smallest write operation we can make do our layout. To align the metaslabs, ZFS iterates over each one, rounds the starting offset up to align with the minimum allocation size, then rounds the total size of the metaslab down so its evenly divisible by the minimum allocation size. Detail on dRAID's metaslab initialization process can be found here and the code for the process is simplified and mocked up below:
group_alloc_size = group_width * 2^ashift
vdev_raw_size = 0
ms_base_size = 2^ms_shift
ms_count = floor(vdev_asize / ms_base_size)
new_ms_size = []
for (ms_index = 0; ms_index < ms_count; ms_index++)
{
ms_start = ms_index * ms_base_size
new_ms_start = ceil(ms_start / group_alloc_size) * group_alloc_size
alignment_loss = new_ms_start - ms_start
new_ms_size[ms_index] =
floor((ms_base_size - alignment_loss) / group_alloc_size) * group_alloc_size
overall_loss = ms_base_size - new_ms_size[ms_index]
vdev_raw_size += new_ms_size[ms_index]
}
Each metaslab will get a bit of space trimmed off its head and/or its tail. The table below shows the results from the first 20 iterations of the above loop:
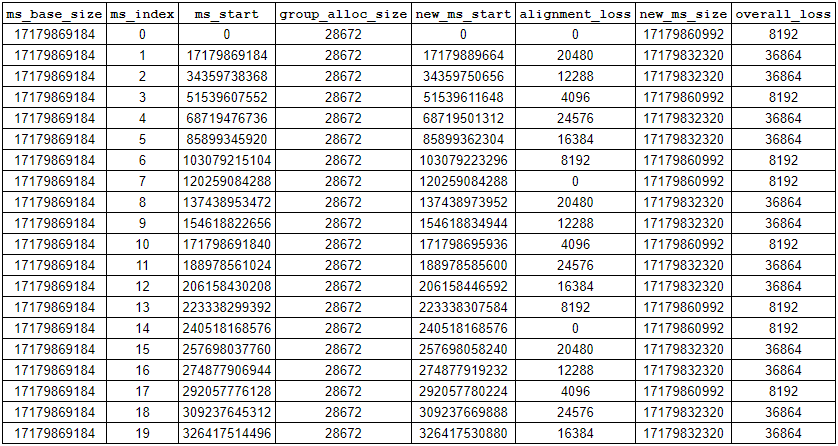
As you can see, we'll end up with some lost space in between many of the metaslabs but it's not very much (at worst, a few gigabytes for multi-PB sized pool). You'll also notice that the metaslab size isn't uniform across the pool; that makes it very hard (maybe impossible Not impossible! See below.) to write a simple, closed-form equation for
Update: On a whim, I asked Google Gemini to examine the block of pseudocode above and try to make a closed-form equation out of it and it actually did it! To make the equation more readable, we'll define the following:
$$ M = \text{ms\_base\_size} = 2^\text{ms\_shift} $$ $$ N = \text{ms\_count} = \left\lfloor \frac{\text{vdev\_asize}}{\text{ms\_base\_size}} \right\rfloor $$ $$ G = \text{group\_alloc\_size} = \text{group\_width} \times 2^\text{ashift} $$We start by defining the period \(P\) which represents how often the alignment pattern repeats in number of metaslabs:
$$ P = \frac{G}{\gcd(M, G)} $$With the period defined, the
I generally don't like to take math and code from AI purely on faith, so spent quite a while staring at all this and prompting Gemini until I got my head wrapped around it. The first step is figuring out where the formula for the period \(P\) came from. If we call \(i\) the index of a given metaslab, and assume the first metaslab starts at byte 0 on the vdev, we'll have some number of misaligned metaslabs until \(i = P\) and things will line up again. For a given metaslab, the ideal starting offset will be \(i \times M\); for the metaslab at index \(P\), its start position is \(P \times M\).For this position to be perfectly aligned, it must be an exact multiple of the group allocation size \(G\). Therefore, we are looking for the smallest positive integer \(P\) where the distance \(P \times M\) is also a perfect multiple of \(G\).
The smallest non-zero distance that is simultaneously a multiple of \(M\) and a multiple of \(G\) is, by definition, the least common multiple (LCM) of \(M\) and \(G\). So, the byte offset where the pattern resets is \(\text{lcm}(M, G)\). Since that distance is also equal to \(P \times M\), we can set up the equation:
$$ P \times M = \text{lcm}(M, G) $$We can divide both sides by \(M\) to solve for \(P\):
$$ P = \frac{\text{lcm}(M, G)}{M} $$Gemini kindly advised me that the lcm function can easily cause integer overflow when being computed, so we so we convert from least common multiple to greatest common divisor (GCD). We can use the following identity for the conversion:
$$ \text{lcm}(M, G) = \frac{M \times G}{\gcd(M, G)} $$Substitute this identity into our equation for \(P\):
$$ P = \frac{\left( \frac{M \times G}{\gcd(M, G)} \right)}{M} $$The \(M\) in the numerator and the \(M\) in the denominator cancel out, leaving the final, simplified equation:
$$ P = \frac{G}{\gcd(M, G)} $$Plugging in numbers from our example:
$$ P = \frac{28{,}672}{\gcd(17{,}179{,}869{,}184,28{,}672)} = \frac{28{,}672}{4{,}097} = 7 $$We can verify this by looking at the table above and counting the period of the
Ideally, the total raw vdev size would be the total capacity of all metaslabs (\(N \times M\)) rounded down to the nearest group size:
$$ G \left\lfloor \frac{N \times M}{G} \right\rfloor $$However, since ZFS cannot allocate a block that straddles the boundary between two metaslabs, we lose capacity at every boundary that is not perfectly aligned to \(G\). The key realization that Gemini made was that the size of the gap between misaligned metaslabs is always equal to the group allocation size, \(G\). This can be confirmed by looking at the table above, although it's not obvious because when I made the table, I was focusing on the per-metaslab losses. In the table below, I've added a few new columns to help illustrate this:
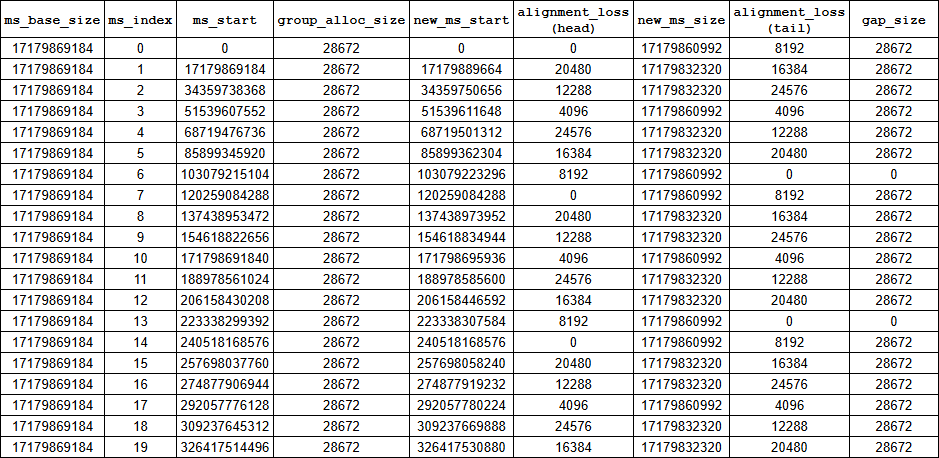
Critically, the
With that in mind, we can more easily calculate the total loss from these misalignments. We first need to count how many misaligned boundaries exist between all the metaslabs on the vdev. We can note that if there are \(N\) total metaslabs on the vdev, there will be \(N-1\) boundaries between those metaslabs. The boundary between metaslab \(i\) and \(i+1\) is aligned only if \(i \times M\) is an even multiple of \(G\). If the boundary is not aligned, we have a \(G\)-sized gap and need to subtract that from our total vdev size. We already know we'll have a perfectly-aligned boundary every \(P\) metaslabs, so the total number of perfectly-aligned boundaries then equals \(\lfloor \frac{N-1}{P} \rfloor\) which means the total number of imperfectly-aligned boundaries equals:
$$ (N-1) - \left\lfloor \frac{N-1}{P} \right\rfloor\ $$Each one of these misaligned boundaries includes a \(G\)-sized gap where space is wasted, so we can then compute the total vdev size by subtracting this wasted space from the ideal vdev size:
$$ G \left\lfloor \frac{N \times M}{G} \right\rfloor - G \left( (N-1) - \left\lfloor \frac{N-1}{P} \right\rfloor\ \right) $$We can distribute the \(G\) on the right-hand side and then factor it out from all three terms to get back to the original equation Gemini provided:
$$ G \left( \left\lfloor \frac{N \times M}{G} \right\rfloor - (N - 1) + \left\lfloor \frac{N - 1}{P} \right\rfloor \right) $$If you're inclined, you can validate this non-uniform metaslab sizing using
As a side note, we could theoretically shift the first metaslab's offset to align with the minimum allocation size and then size it down so its overall size was an even multiple of the minimum allocation size and all subsequent metaslabs (each sized down uniformly to be an even multiple of the min alloc size) would naturally line up where they needed to with no gaps in between. In order to do this, however, the OpenZFS developers would need to add dRAID specific logic to higher-level functions in the code; they opted to keep it simple. The amount of usable space lost to those gaps between the shifted metaslabs really is negligible though, like on the order of 0.00004% of overall pool space.
Once we have the
We start with the recordsize (which we'll assume is the default 128KiB) and figure out how many sectors (each sized at \(2^\text{ashift}\)) it takes to store a block of this size:
$$ \frac{128 \times 1{,}024}{2^{12}} = 32 \text{ sectors} $$Then we figure out how many redundancy groups this will fill by dividing it by the number of data disks per redundancy group (not the total group width, just the data disks; parity disks don't store data!):
$$ \frac{32}{5} = 6.4 $$We can't fill a partial redundancy group so we round up to 7. We then multiply this by the redundancy group width (including parity) to get the total number of sectors it takes to store the 128KiB block:
$$ 7 \times 7 = 49 $$This configuration consumes 49 total sectors to store 32 sectors worth of data, giving us a ratio of
$$ \frac{32}{49} = 0.6531... $$Just like with RAIDZ, we round this down to be a whole fraction of 512 to get the deflate ratio:
$$ \frac{\left\lfloor \frac{32}{49} \times 512 \right\rfloor }{512} = \frac{334}{512} = 0.6523... $$We end up with \(\frac{334}{512}\) (or 0.6523...) as the deflate ratio for this configuration. We multiply the
We compute slop space the same as we did above (we exceed the max here so we use 128 GiB) and remove that from our usable space to get final, total usable for this pool:
$$ 198{,}299{,}564{,}324{,}288 - (128 \times 1{,}024^3) = 198{,}162{,}125{,}370{,}816 \text{ bytes} $$We can validate this with
jfr@zfsdev:~$ sudo zfs list -p tank
NAME USED AVAIL REFER MOUNTPOINT
tank 4545072 198162120825744 448896 /tank
By adding the values in
Closing Thoughts
The RAIDZ example used VirtualBox with virtual 18TB disks that hold exactly 18,000,000,000,000 bytes. Real disks won't have such an exact physical capacity; the 8TB disks in my TrueNAS system hold 8,001,563,222,016 bytes. If you run through these calculations on a real system with physical disks, I recommend checking the exact disk and partition capacity using
We took a shortcut with the dRAID example because we didn't need to include swap space. We used
sudo truncate -s 8TB /var/tmp/disk{0..39}
/sbin/losetup -b 4096 -f /var/tmp/disk{0..39}
zpool create tank -o ashift=12 draid2:5d:20c:1s /dev/loop{0..19} draid2:5d:20c:1s /dev/loop{20..39}
It's worth noting that none of these calculations factor in any data compression. The effect of compression on storage capacity is almost impossible to predict without running your data through the compression algorithm you intend to use. At iX, we typically see between 1.2:1 and 1.6:1 reduction assuming the data is compressible in the first place. Compression in ZFS is done per-block and will either shrink the block size a bit (if the block is smaller than the recordsize) or increase the amount of data in the block (if the block is equal to the recordsize).
We're also ignoring the effect that variable block sizes will have on functional pool capacity. We used a 128 KiB block because that's the ZFS default and what it uses for available capacity calculations, but (as discussed above) ZFS may use a different block size for different data. A different block size will change the ratio of data sectors to parity+padding sectors so overall storage efficiency might change. The calculator above includes the ability to set a recordsize value and calculate capacity based on a pool full of blocks that size. You can experiment with different recordsize values to see its effects on efficiency. Changing a dataset's recordsize value will have effects on performance as well, so read up on it before tinkering. You can find a good high-level discussion of recordsize tuning here, a more detailed technical discussion here, and a great generalized workload tuning guide here on the OpenZFS docs page.
Please feel free to get in touch with questions or if you spot any errors! jason@jro.io
If you're interested in how the pool annual failure rate values are derived, I have a write-up on that here.