OpenZFS, arguably the heart of TrueNAS, is the open-source file system and volume manager based on Sun/Oracle's ZFS. ZFS development began at Sun Microsystems in 2001 with the aim of completely reframing how systems administrators manage their storage systems. Its original development team outlined several guiding principles that still shape the project today: storage should be flexibly-pooled, always consistent, self-healing, and simple to manage. The claim that ZFS is the "final word in file systems" comes from a presentation its original creators gave in 2008.
ZFS Terminology
ZFS uses a lot of jargon that can make reading documentation and other guides pretty confusing to newcomers. This section serves as a quick reference for some of the more common ZFS (and broader storage landscape) lingo you'll come across.
- Vdev: ZFS virtual device, a group of one or more disks usually with some redundancy like mirroring or RAIDZ.
- Mirror vdev: Every disk in the vdev gets an identical copy of all data. Usually consists of 2 disks but can have more.
- RAIDZ1: Like RAID5, some number of data disks plus one parity disk (N+1).
- RAIDZ2: Like RAID6, some number of data disks plus two parity disks (N+2).
- RAIDZ3: Some number of data disks plus three parity disks (N+3).
- dRAID: A new, distributed RAID vdev format that mixes spare space into the vdev.
- Pool (or "zpool"): The logical ZFS volume or array consisting of one or more vdevs.
- Resilver: ZFS term for rebuilding a pool after a drive fails and is replaced.
- Healing Resilver: Another term for the "traditional" resilver mentioned just above.
- Sequential Resilver: A faster resilver created for dRAID that does not validate block checksums; needs to be followed by a scrub. Can also be run on mirrored vdevs.
- Rebalance: A dRAID-specific operation that re-adds spare space to a vdev after a failed drive has been physically replaced.
- Scrub: Automatic scan of a pool to verify checksums and correct data corruption.
- Dataset: The logical container where ZFS stores data. There are four types of datasets: file systems, volumes, snapshots, and bookmarks. "Dataset" can also refer to a file system dataset.
- Zvol: Shorthand for a volume dataset. A zvol acts as a raw block device. ZFS carves out a chunk of disk space to be used by block sharing protocols like iSCSI.
- ARC: Adaptive Replacement Cache, the algorithm used by ZFS to cache data. Also refers to the cache itself which exists in a system's main memory. The ARC is shared by all pools on a system.
- L2ARC: A second tier of cache under the ARC. Despite its name, L2ARC uses a simple ring buffer algorithm and is typically deployed on one or more fast SSDs. L2ARCs are assigned per pool.
- ZIL: The ZFS intent log. Stable storage that acts as a temporary landing zone for incoming sync writes. Every pool has a ZIL regardless of whether the pool has a SLOG.
- SLOG: A separate device for the ZFS intent log (sparate log device, hence SLOG device). Added to a pool as a fast SSD if it's handling latency-sensitive sync writes. Like the L2ARC, it is assigned per pool.
- Snapshot: A read-only historical reference copy of a dataset. Only consumes space based on changed data since the snapshot was taken.
- Clone: A mounted, read/write copy of a snapshot. Can be used to recover files from a snapshot or to provide a new, separate working set of data.
Virtual Devices (vdevs)
In ZFS, disks are grouped into virtual devices (or vdevs) usually with some form of redundancy/protection against disk failure. A ZFS pool may have one or more vdevs; if a pool has more than one vdev, they're striped together to form one giant bucket of storage. A vdev's redundancy might be based on simple multi-disk mirrors or RAIDZ where administrators can pick from single-, double- or triple-disk parity protection. There are several other types of vdevs that we'll cover later on, but primary pool vdevs come in a few different flavors:
- Striped: This is the simplest type of vdev and uses just a single disk, meaning it offers no protection against disk failure whatsoever.
- Mirror: This vdev writes an identical copy of every block to multiple drives. Usually, a mirror vdev only has 2 drives, but ZFS supports 3-way and higher mirrors as well. A pool with mirrored vdevs behaves somewhat like a RAID10 array and it's not uncommon to see a pool of ZFS mirrors called a RAID10 layout.
- RAIDZ1: The RAIDZ1 vdev is conceptually similar to a RAID5 array in that it groups a number of data disks with a single parity disk. The single parity disk protects the RAIDZ1 vdev against a single drive failure.
- RAIDZ2: As above, the Z2 vdev is conceptually similar to a RAID6 array. It groups a number of data disks with two parity disks and protects against one or two drive failures in the vdev.
- RAIDZ3: This vdev extends the protection to three parity disks and protects against one, two, or three drive failures in the vdev.
- dRAID: A new, distributed RAID vdev format that mixes spare space into the vdev. Supports single, double, and triple parity protection along with virtual, distributed spares. Covered extensively below.
A "pool" in ZFS is simply a set of one or more of these vdevs. A pool with multiple vdevs will have data spread across those vdevs in a process called "striping": the first block goes to the first vdev, the second block to the second vdev, and so on until you write to the final vdev and loop back around to the first again. This method of combining multiple vdevs into a single pool provides no extra redundancy whatsoever, meaning the only protection against disk failures in ZFS is the redundancy built into the vdevs themselves. The extremely important implication here is this: if a single vdev in a ZFS pool fails, the entire pool is lost.
These slides visually depict how data is spread across the different types of vdevs in a ZFS pool:
We'll introduce an important bit of ZFS nomenclature here that will be useful when discussing different pool and vdev layouts: the vdev "width". The width of a vdev is simply the number of drives in that vdev. For example, a RAIDZ2 vdev with 6 disks could be called a "6-wide RAIDZ2 vdev". (Mirrored vdevs are usually referred to as "2-way" or "3-way" mirrors.) We can write "6-wide RAIDZ2" in shorthand as "6wZ2". We'll use this notation as we continue to discuss ZFS pool and vdev layouts.
Although ZFS allows administrators to mix vdev widths and types in a single pool (i.e., 2 mirror vdevs and 1 RAIDZ2 vdev), this is strongly discouraged. The resulting pool will have strange performance characteristics that vary based on which vdev ZFS happens to read from or write to. Because a single vdev failure means total pool failure, a pool with mixed vdev widths and types will only be as reliable as its least-reliable vdev (in the previous example, that would be the two mirror vdevs). You can also technically mix different size drives in a single vdev, but ZFS will treat all drives as if they were the smallest drive size you use. For example, if you use one 1TB drive and nine 20TB drives, ZFS will treat all ten drives as if they were 1TB each. You can have vdevs that each use different size drives (i.e., one vdev with all 4TB drives and another with all 6TB drives) but this will cause data imbalance as some vdevs will end up getting more I/O than others. For this reason, mixing vdev capacities is discouraged.
When designing a RAIDZ pool, it may be tempting to put all your drives in one enormous vdev to maximize usable capacity. Be aware that, even for basic home use, it's strongly discouraged to use a vdev width greater than 11 or 12. Resilvering and scrubbing (ZFS processes we'll discuss later on) will take significantly longer on very wide vdevs which results in long intervals where data is at-risk and performance is poor. Very wide RAIDZ vdevs can also result in more partial-stripe writes, which (as we'll cover just below) will reduce overall storage efficiency.
If using RAIDZ1 on hard disks, be advised that a single disk failure during a pool resilver could result in complete data loss. For this reason, RAIDZ1 is generally discouraged on all but the smallest hard-disk-based pools. You can safely use RAIDZ1 with hard disks if you understand the risks and keep important data backed up elsewhere, but it's advisable to keep vdev width small (fewer than 6 disks) and to use lower-capacity hard drives.
If you have more than ~10 drives in your pool, try to fit a hot spare in your chassis. If you can't fit a hot spare, you can order an extra drive to keep on the shelf. As you expand your pool, try to have 1 spare drive for every ~20 or 30 pool drives (or whatever ratio makes you feel comfortable). SSDs are far more reliable (and typically fail much more predictably) than HDDs so you can be a bit looser with the spare ratio on all flash pools.
In the OpenZFS Tuning section below, we'll go into great detail on how to size RAIDZ vdevs to minimize overhead.
Pool Performance, Capacity, and Reliability
Storage administrators naturally want to configure a pool that maximizes performance, usable capacity, and reliability. Of course, we need to carefully balance the tradeoffs between these three variables (and an ever-important fourth variable: system cost). iXsystems has a whitepaper which was written by the author of this guide that covers the interplay of performance, capacity, reliability, and cost that can be found here.
Slides covering this subject at a higher-level can be found below:
With regard to pool performance, we can summarize the information in this whitepaper by noting a few key things:
- ZFS pool performance will scale in a roughly linear nature with the number of vdevs in the pool. In other words, we would expect a pool with 10 vdevs of a given type to perform about twice as fast as a pool with 5 vdevs of that same time (assuming there are no other bottlenecks in the system).
- The performance of mirror vdevs scales very well. Each 2-way mirror vdev should offer 2x the random and sequential read performance of a single disk and 1x the random and sequential write performance. These effects are compounded in pools with multiple vdevs. A pool with 5x 2-way mirror vdevs would then see roughly 10x the random and sequential read performance of a single disk and 5x the random and sequential write performance of a single disk.
- The sequential read and write performance of RAIDZ vdevs scale with the quantity of data disks in that vdev. If a RAIDZ1, Z2, or Z3 vdev has 5 data disks, we would expect that vdev to deliver about 5x the sequential performance of a single disk. The random read and write performance of a RAIDZ vdev will be roughly that of a single disk. As with mirrors, these effects compound in pools with multiple vdevs.
Administrators can get a rough estimate of pool capacity by summing the size of all the data disks in the pool. For example, a pool with two 6wZ2 vdevs using 10TB drives would have approximately 2 vdevs * 4 data disks per vdev * 10TB = 80TB of usable capacity. To further refine this estimate, we can convert from terabytes to tebibytes by doing 80TB * 1000^4TiB/1024^4TB = 72.76TiB. If you actually went out and bought a set of twelve 10TB disks and put them in a pool like this, you would notice that usable capacity is slightly lower than 72.76TiB. The reason for this has to do with ZFS' very complex on-disk structure. As we discussed above, there are various sections on each of the disks in a ZFS pool that are left unusable in order to provide some extra data protection, account for the way blocks are spread across the disks' sectors, or simply to optimize performance. Again, for an in-depth look at how this on-disk structure impacts usable capacity, you can review the calculator and guide here.
Determining relative vdev and pool reliability can also be more complicated than it might initially appear. Intuitively, you might think that a pool with two 6wZ2 vdevs (i.e. four parity disks total) would be statistically less likely to fail than a system with a single 12wZ3 pool (three parity disks). After digging into the complex world of probability, you'll actually find that the 12wZ3 pool is statistically less likely to fail than the 2x 6wZ2 pool. To put things simply, the Z2 pool can be brought down by three disk failures inside of either vdev while the Z3 will only be brought down after four disk failures; there are just more possible scenarios in which the Z2 pool fails compared to the Z3 pool. If you're interested in the probability calculation process, you can review the page here.
Expanding a ZFS Pool
There are currently two methods to expand a ZFS pool: add more vdevs to the pool or replace all the disks in a vdev with higher-capacity disks.
If you add another vdev to a pool, it should use the same capacity drives and the same layout and width as the rest of vdevs in the pool. Technically, ZFS will let you add a 6-disk RAIDZ1 vdev with 18TB drives to a pool with 4TB drives in mirrored vdevs but that doesn't mean it's a good idea. As discussed in the vdev section, you'll get unpredictable performance and pool reliability.
If you're comfortable straying slightly outside best practices, you can use different size disks in the new vdev but they should really really be in the same layout as the other vdevs in the pool. If you do use different size disks in a new vdev, you'll end up with some data imbalance due to how ZFS spreads incoming writes across vdevs in a pool. The one new vdev may end up seeing a disproportionately large amount of I/O which could bottleneck pool performance. If your workload isn't performance sensitive, this might be acceptable.
When you add a new vdev to a pool, ZFS does not have any automatic mechanism to rebalance data across the new drives. As data turns over and is changed and rewritten naturally by client systems, it should spread out across the newly-expanded pool. If you are concerned about imbalance, you can either expand when your pool is at 70-75% full or manually rebalance by rewriting all your data. If you don't have a second system to copy off all your data, you can make a new temporary dataset, move (not copy!) all the data from the original dataset to the temporary one, and then move it back to the original. This method is less than perfect, but it should get your data spread more evenly across all the new drives.
The second method to expand a pool is to replace all the drives with larger capacity ones. If you have free bays available, you can install the new, larger drives in those bays and use ZFS' replace function to build the new drives into the pool without having to pull any live drives. Once you replace all drives in a vdev, the pool will automatically expand to reflect the additional capacity.
You can replace multiple drives at once in parallel if you have multiple drive bays available. If you don't have free drive bays available, you can remove drives from the pool and replace them one at a time, but removing redundancy from your pool this way is very risky. Try to find a way to attach another drive without pulling pool drives; creativity is encouraged. You can even use a USB3 SATA adapter if needed (the new drives will work just fine once moved into a proper SATA/SAS bay after they're added to the pool).
One of the most-requested OpenZFS features is the ability to grow RAIDZ vdevs by one or two disks at a time. This was very recently added in a pull request on the OpenZFS GitHub but has been awaiting code review for quite some time. This feature will make its way into TrueNAS once it's been tested by the OpenZFS community, but it will likely take some time. You can follow along with the review process here.
Datasets and Zvols
A dataset in ZFS is the logical container where you store all your data. There are four types of datasets: file systems, volumes, snapshots, and bookmarks. In this section, we'll focus on the first two.
File System Datasets
File system datasets (commonly referred to simply as "datasets") are used in TrueNAS to back file shares like SMB and NFS. They behave a lot like a normal folder in Windows: you can put files and folders and even other ZFS datasets inside of a file system dataset. Unlike normal file system folders however, you can change all sorts of settings that govern how stuff in that dataset is stored by ZFS. In a dataset, you can tune compression and checksumming, you can enforce disk space quotas and reservations, you can even change the maximum size of the on-disk blocks to optimize storage performance for a specific workload. Perhaps most importantly, you can also capture snapshots of a dataset. We'll discuss snapshots in more detail later on, but suffice to say snapshots provide an extremely light-weight and simple method for creating restore points on datasets.
When you create a new pool in ZFS, it automatically adds a root-level dataset to that pool. It's best practice to not drop all your stuff directly in this dataset and then share it out with TrueNAS. This will limit your flexibility to create separate shares and volumes down the road. Instead, it's recommended to create one or more datasets under this root dataset and drop your stuff in those sub-datasets. The filesystem structure might look like this (**dir_name** indicates a dataset while dir_name indicates a standard directory):
**Root Dataset**
**Share 1**
Documents
Games
Movies
Music
Photos
**Share 2**
Desktop backup
Laptop backup
With this structure, you can easily add more shares later on, you can change the dataset parameters of **Share 1** and **Share 2** to fit the data being stored in each, and you can create different snapshot schedules for each share to balance disk space usage with restore point availability.
Many seasoned ZFS veterans would even take things a step further and structure things as follows:
**Root Dataset**
**Share 1**
**Documents**
**Games**
**Movies**
**Music**
**Photos**
**Share 2**
**Desktop backup**
**Laptop backup**
In this example, all of the top-level directories in each share are also ZFS datasets. You would still share out **Share 1** and **Share 2** and from the perspective of the file sharing clients the data would be identically structured to the example above but the ZFS admin would be able to further dial in the settings on each sub-dataset.
Volume Datasets (Zvols)
A volume dataset (usually referred to as a "zvol") acts as a raw block device. ZFS carves out a chunk of disk space to be used by block sharing protocols like iSCSI. You'll only use zvols in TrueNAS if you need to use iSCSI to support your storage needs. (We'll discuss iSCIS vs. SMB and NFS in another section.) Unlike file system datasets where ZFS is managing a logical hierarchy of the files and folders, a zvol is effectively raw disk space whose contents can not easily be viewed from the TrueNAS. The zvol's logical file and folder structure would be created and managed by a client system which mounts the block device over the network and thus that logical structure is obscured to the TrueNAS.
Because zvols are basically raw disk space, the settings you can tune in them are a bit different than in file system datasets. You can still set things like compression and block size settings, but other settings like per-user quotas don't make sense. After all, ZFS does not have a view into the file system applied to a zvol so it doesn't know what users are writing to what directories.
By default, file system datasets in ZFS can use up to the full capacity of the pool. Zvols on the other hand need to have a size specified. You can choose if ZFS should reserve this entire space as soon as the zvol is created (called "thick provisioning") or if you want ZFS to only allocate space as blocks are written to the zvol (called "sparse" or "thin provisioning").
If you opt to run your zvols with thin provisioning enabled, you need to be careful not to let your underlying pool get overly full. It's possible to over-commit the storage and cause all sorts of strange issues if the pool fills up before the zvols do. For example, if you have a 5TiB pool, nothing will stop you from creating 10x 1TiB sparse zvols. Obviously, once all those zvols are half full, the underlying pool will be totally full. If the clients connected to the zvols try to write more data (which they might very well do because they think their storage is only half full) it will cause critical errors on the TrueNAS side. Even if you don't over-commit the pool (i.e., 5TiB pool with 5x 1TiB zvols), snapshots can push you to the one hundred percent full mark.
Obviously, if the pool is one hundred percent full, all writes to that pool will suddenly halt. You may experience other strange issues if your pool is totally full like certain basic shell commands failing; these commands often temporarily need tiny bits of disk space to run. The filesystem applied to the zvol you just over-filled will also have some issues including corruption of the most-recently-written data. Expect some amount of data loss and to have to run a filesystem repair utility after fixing the underlying capacity issue.
Of course, the way to remedy this situation is to delete some stuff from the pool, but the copy-on-write nature of ZFS (which we'll discuss in detail below) means that you actually need a tiny bit of free space available on the pool to delete data. ZFS does implement some safeguards (like SPA slop space) to help avoid this out-of-space situation but it's very possible to blow right past those safeguards if you aren't careful. If you do fill every last block on your pool, often the only way to fix it is to expand the pool either by adding a new vdev or replacing all disks in a vdev with larger ones. Once you have some free space available, you'll be able to delete some of the existing data. Be aware that pool and vdev expansions are usually one-way operations: you can't remove the vdev you just added (unless your pool is all mirror vdevs) and you can't go back to smaller-capacity drives in the expanded vdev.
Thick-Provisioned Zvols and Snapshots
We'll cover snapshots in more detail in a couple sections, but by default, ZFS snapshots only track changes in data since the last snapshot was taken. Say you have a 10TiB dataset, you take a snapshot, and then change 100MiB worth of data on the dataset; the snapshot will consume 100MiB of extra space on the pool because it has to track the original version of all of that data.
If you enable thin or sparse provisioning on a zvol, snapshots behave as described above: snapshots only track data deltas.
With thick-provisioned zvols, things can be slightly more complicated. If you run a zvol with thick provisioning (i.e., you disable sparse provisioning), you're essentially having the system reserve all of the space on that zvol. If you create a 10TiB thick-provisioned zvol, you will see a 10TiB reservation set on the ZFS pool associated with that zvol (ZFS creates this as a "refreservation", or a reservation only on the parent dataset and not any of its children). As you write data to the zvol, that reservation shrinks: if you write 1TiB of data, the reservation will shrink to 9TiB. The system needs to make sure you always have 10TiB of total capacity on that zvol at all times.
Because of this reservation mechanism, snapshots on thick-provisioned zvols take up extra space based on how full that zvol is. If you snap the 10TiB zvol that has 1TiB of data in it, you will need 1TiB of extra space outside of the zvol to store that snapshot, thus your pool will have 11TiB total used: 1TiB is the data in the zvol, 9TiB is the remaining reserved space in the zvol, and 1TiB is being reserved by the snapshot. If you write an additional 1TiB to the zvol and take another snapshot, you'll see your pool usage jump to 12TiB: 2TiB used by data in the zvol, 8TiB by the reserved space on the zvol, and 2TiB reserved space by the snapshots.
The reason it needs to track this snapshot data outside of the zvol is to ensure that there is always 10TiB of space inside the zvol. If you deleted that 2TiB of data from the zvol but kept the snapshot, ZFS still needs to provide 10TiB of storage on the zvol while still tracking the 2TiB of data you just deleted.
To further justify this, we can provide a counter-example scenario where ZFS does not behave this way: you have a 10TiB pool with an 8TiB thick-provisioned zvol. Because it's thick-provisioned, ZFS is supposed to ensure you always have 8TiB of space in the zvol to work with. You fill the zvol with 8TiB of data, create a snapshot of the zvol, and then delete all of the data from the zvol. Because you snapped the zvol before deleting the data, ZFS needs to track all 8TiB of that data even after you deleted it. In other words, your 10TiB pool has 8TiB of data in it that doesn't exist in the zvol, leaving only 2TiB of space in the zvol. Obviously, this is not compatible with the ensure-you-always-have-8TiB-of-space-in-the-zvol promise of thick provisioning.
You can avoid this additional space "penalty" by enabling thin provisioning on the zvol, but (as mentioned in the previous section) you need to make sure you don't over-allocate your storage by accident. You could for example create 10x 10TiB thin-provisioned zvols on a 50TiB pool and the clients would not actually know how full the underlying storage is. If the pool fills up and the client tries to write additional data, you will cause some data corruption in the zvol and other strange issues on the pool.
In short, you can either:
- Use thick-provisioning, not worry about closely monitoring space usage, but you'll have to deal with extra space allocation from snapshots, or
- Use thin-provisioning, not have any extra space allocation for snapshots, but you'll need to keep an eye on pool capacity.
If needed, you can switch a zvol from thin- to thick-provisioned by setting refreservation=auto on that dataset. To switch it back to thin-provisioned, set refreservation=none.
Note that file system datasets exhibit this behavior as well if you add a refreservation and create a snapshot. Large reservations and refreservations are not as common for file system datasets, so you're less likely to come across this phenomenon there.
Copy on Write
Copy on Write (or "CoW") is a mechanism employed by ZFS to help protect data against corruption after a sudden system crash or power failure. CoW also enables light-weight snapshots in ZFS.
ZFS' on-disk data structure is a kind of tree (the computer science kind, not the grow-in-the-forest kind). In a simplified view of this data tree, we have a root block at the very top called an "uberblock" which points to another block underneath it. That next block points to two more blocks which in turn each point to two more blocks, so on and so forth. If you were to look at the tree in layers you would have one uber block on top, then one block under that, then two blocks, then four, then eight, then 16, then 32, etc.
The pointers inside these blocks are usually visualized as arrows on a tree diagram but in reality, they're just designated spots inside each block that store the on-disk address of the next block down. These blocks under the uberblock are called "indirect blocks" and if you recall studying exponents in school, you'll know that the number of indirect blocks starts to grow very rapidly as we move down the tree. At a certain point, we reach the bottom of the tree and the last layer of indirect blocks point not to other indirect blocks but rather to "leaf" blocks that store the actual user data in ZFS.
Each uber block and indirect block contains more than just pointers to the next blocks in the tree. They also store information on where the block is physically kept on-disk, when it was originally written, and a checksum of the blocks that they point to. This checksum of the next block down in the tree is one of the most important features of the indirect block because it allows us to quickly validate that nothing has changed in the on-disk structure without walking through the whole data tree. To reiterate, the indirect blocks don't store a checksum of their own data but rather a checksum of the blocks they point to. If you've studied cryptography or computer science, you may be familiar with this approach as a Merkle tree.
For visual learners, a simple version of the block tree as well as more information on CoW and snapshots can be find in the slides here:
We now have a nice (if massive) tree structure of blocks with checksums for all the blocks top to bottom but we still haven't introduced any Copy-on-Write; that comes in when we make updates to the block tree. On a traditional file system, on-disk blocks are usually overwritten in place, meaning if you're editing a photo and you save your updates, the filesystem simply overwrites the old data with the new data. Usually, this simple approach is fine until you have a power outage or system crash while writing out some updates to a file. Once you power your system back up, you'll likely find the photo is corrupted because the write failed halfway through. Depending on how important this photo was, its corruption might be a mild inconvenience or extremely disruptive. If this crash happened while one of your critical system files was being updated, you could even end up losing the whole file system.
Copy on write avoids this by never overwriting data in-place. Instead, it writes a new, updated copy of the data to an empty place on disk (hence "copy on write") and then works its way up the block tree updating all the indirect blocks to point to this new location. Those indirect blocks aren't updated in-place either, each one has its modified copy written to a new location on disk, one after the other. The update process works its way up the block tree until finally the uberblock gets a CoW update as well. The moment the new, updated uberblock is done writing, the write operation is completed and ZFS can mark all the old versions of each block to be freed.
If power were lost or the system were to crash even a microsecond before the last bit of data to the new uberblock was written out, ZFS would know that uberblock was invalid and would look for the next most recent valid uberblock to mount. In this way, the failed write will be totally rolled back and the block tree will still be in its most recent consistent state. The copy-on-write strategy allows ZFS to pass from one consistent on-disk state to its next consistent on-disk state without ever passing through an inconsistent state.
Obviously, if we do this whole process of CoW updates all the way up the tree for every single new write, our storage would be unusably slow. Instead, ZFS aggregates incoming write data in RAM inside a data structure called a "transaction group" or "txg". Every few seconds ZFS will flush all this data from the transaction group out to disk by walking through the copy-on-write process for everything all at once. By leveraging txg's to bundle lots of small, random writes into one large sequential write, we can reduce write latency considerably. We'll discuss this process more when we cover the ZIL and SLOG devices.
Snapshots and Clones
The copy-on-write process that ZFS leverages also enables a very effective and transparent snapshot mechanism. The slides linked below cover how snapshots work:
If you create a snapshot, ZFS flags the root block in the block tree. As you make updates to the data (either changing it, deleting it, or adding to it), instead of freeing unreferenced blocks after the CoW process completes, it preserves any block referenced by a snapshot. Changed blocks that are not referenced nor by the live filesystem by the snapshot are freed as normal. This means that ZFS is only tracking blocks that have been modified since the snapshot was created.
In practice, if you have a 100TiB dataset and you take a snapshot, initially that snapshot will consume only a few kilobytes of disk space. If you add new files to the snapped dataset, the snapshot will still only consume a few kilobytes of disk space: everything in the snapshot still exists in its same state on the live dataset, so we don't need any extra disk space to track that. As you modify and delete files in the dataset, you'll see the snapshot size start to grow. If you delete 1TiB of data from the dataset, you'll see the snapshot consume 1TiB of space to track that deleted data while the live dataset is only consuming 99TiB. If you then modify another 1TiB of data from the dataset, the snapshot will consume 2TiB of disk space (tracking both the deleted data and the original version of all the modified data) while the live dataset consumes 99TiB (not 98TiB; we didn't delete anything after the first 1TiB, just modified it).
TrueNAS allows you to capture snapshots automatically on very frequent intervals and supports custom cron statements in the snapshot schedule config. If you have enough storage, you can keep tens of thousands of snapshots on a TrueNAS system before you'll see much of a performance impact. A few words of warning though: it's discouraged to capture snapshots more frequently than every 5 minutes and the process of deleting snapshots can be resource intensive. If you try to delete a batch of several thousand snapshots all at once, you may see a performance impact while the operation completes, especially on systems with large pools. ZFS has to go through the whole block tree and figure out which blocks to free up and this takes a long time.
When capturing a snapshot either manually or via an automated task, you can do so recursively. This can be helpful if you have a parent dataset with 100 children (either datasets or zvols) and want to snap all of them at once. By capturing a recursive snapshot of the parent, you'll end up with 101 total snapshots: one for the parent and 100 for the children.
Some enterprise storage systems let administrators set aside dedicated storage specifically for saving snapshot deltas. The advantage of this approach is that the snapshot storage (presumably) doesn't have to be as fast as the primary data storage. The disadvantages are that snapshot deltas need to be somehow transferred from the primary pool to the secondary pool and that this added complexity often comes with increased system cost. ZFS does not support storing snapshot deltas on a separate storage pool; all snapshot data will reside on the pool itself. You can replicate those snapshots to a second pool or a second system, but (as we'll cover below) that means having a full second copy of the data.
ZFS snapshots work on both file system and volume datasets. It's important to note that if your iSCSI LUNs are mounted as VM datastores, capturing a snapshot will not produce an application-consistent backup. ZFS and TrueNAS only know what is currently on disk, thus if the VM has any data in memory that has yet to be flushed out to disk, the snapshot will miss that data. If you're using VMware, you can configure VMware Snapshots to address this shortcoming. By connecting TrueNAS to the VMware host or vCenter instance, TrueNAS can ask VMware to quiesce data on a datastore before capturing a snapshot. By quiescing the disks in VMware before taking a snapshot, we have a better chance of capturing a fully-consistent backup of the system.
If you need to recover data from a snapshot, ZFS provides a function called "cloning" which essentially mounts a read/write copy of that snapshot. If you just need to fetch a single file, you can share that cloned snapshot out or go in via CLI and copy the file from the snap to the live version of the dataset. You can also use that clone as a starting point for a new dataset if needed. Modifications to the clone will be tracked separately from the original version of the dataset. As the two versions (the original and the clone) diverge, ZFS will consume more space. ZFS provides the ability to "promote" a cloned snapshot if you ever want to totally delete the original, live version of that dataset and just use the clone instead.
ZFS also provides the ability to issue a full roll-back of a dataset to a given snapshot. This is somewhat of a nuclear option as everything in the whole dataset will be rolled back (potentially undoing useful work). If you're hit with ransomware though, a roll-back may be your best option. Usually, you'll want to make one last snapshot of the live dataset before doing a roll-back so that way you can easily undo it if needed.
There is one final, slightly easier way to recover data from snapshots using the built-in hidden snapshot directory. See the Snapshot Directory section under ZFS Tuning to learn how to enable this directory. With the directory enabled, you can browse old versions of the file system using a hidden folder in the root directory of the live dataset. Copy files from this hidden folder back to the live dataset to quickly recover.
When you perform an OS upgrade on TrueNAS, it will automatically snap the boot volume before making any changes. This provides an easy way to roll back after an update if something went sideways. Note however that upgrades to the ZFS pool itself are one-way operations and can not be undone using snapshots.
Replication and Bookmarks
ZFS includes a built-in replication method that can create an identical block-level copy of a snapshot on another ZFS system. The replication engine in ZFS is exposed through the UI in TrueNAS to make setup easier, but under the hood, it uses the zfs send and zfs receive commands to actually move the data around.
ZFS replication works on snapshots, not on live datasets. Live datasets are a moving target: data will be constantly changing during the replication process which makes everything much more complicated. By working on a static, read-only version of the dataset, we can better ensure end-to-end consistency of the data.
After the first snapshot of a dataset is fully transmitted to the target system (a process commonly called "seeding"), subsequent replication runs of later snapshots on the same dataset will just transmit any changes made in more recent snapshots. The target system will save not only the most recently-transmitted snapshot, but all of the older snapshots as well. This makes point-in-time restores much easier. TrueNAS provides the ability to configure a snapshot retention schedule on the target side that is different from the receiving side. You may want your backup server to retain snapshots for a longer period of time than your live production server.
By default, the replication target dataset on the receiving side will be in a read-only state. Although this can be changed, making modifications to the target dataset outside of the replication process will cause problems the next time the replication runs. It will only transmit changes since the last snapshot so if the baseline is off, the result will be unpredictable. ZFS will generate an error in this scenario rather than corrupting data but you'll have to either roll back the target dataset or re-replicate everything to a new dataset.
Unlike file-level replication engines such as rsync, ZFS replication works at the block level and does not need to do a full scan of changes before transmitting data. Changes are already tracked as part of the native snapshot process, so ZFS can put data on the wire as soon as the connection with the remote system is made. This also means that replicating lots of tiny files should be much faster than with something like rsync because we don't have to constantly switch between files during the transmission.
ZFS replication on TrueNAS typically runs through an SSH connection so it is encrypted in transit by default. You can also optionally replicate an unencrypted dataset such that it lands in an encrypted state (say, at an untrusted location). That resulting dataset can be scrubbed and replicated again without being unlocked.
ZFS bookmarks are a space-saving extension to snapshots that can potentially be useful when leveraging incremental replication. A bookmark is created from a snapshot rather than from a dataset. Unlike a snapshot, a bookmark does not keep track of any changes in data; instead it only tracks the "birthtime" of the most recently-created block in that snapshot. Because it's essentially only storing a small timestamp, bookmarks take up almost no space at all on the pool.
When running incremental replication, the underlying zfs send command will expect a starting snapshot and an ending snapshot. ZFS will then roll up all snaps between those two and transmit them to the replication target. If the replication target already has a full copy of the starting snapshot (as they would if you're running regular incremental replication), zfs send lets you specify the bookmark of the starting snapshot instead of the snapshot itself. In fact, you can bookmark the starting snapshot, delete that snapshot from your system, and the replication will still work as expected.
As an example, imagine you have a system creating daily snapshots of a dataset called "office" and replicating them to a second system. After the office@jan15 snapshot finishes replicating to the second system, you may want to free up a bit of space on the primary system. You can create a bookmark of the office@jan15 snapshot on the primary system (bookmarks are denoted with a "#" symbol); we'll call it office#jan15-bookmark. Once the bookmark is created, you can delete the office@jan15 snapshot from the primary system. The next night, you want to replicate the new office@jan16 snapshot to the secondary system. To do this, you would specify office#jan15 as the starting snapshot (or bookmark in this case) and office@jan16 as the ending snapshot. Even though the@jan15 snapshot itself is gone, ZFS can still look at the timestamp stored in the #jan15 bookmark to figure out what blocks have changed between then and the @jan16 snapshot.
The bookmark function of ZFS is not exposed in the TrueNAS UI. If you want to leverage bookmarks in your replication jobs (or for any other purpose), you'll need to do so via the shell.
The Adaptive Replacement Cache and L2ARC
The adaptive replacement cache (or ARC) is an advanced caching strategy used by ZFS to accelerate data access. Before we dive headfirst into the ARC, it will be useful to review data caching and why it's so important for large storage systems.
The Motivation for Caching
Caching algorithms attempt to predict what data users will need before they request it. They can keep that data on faster storage, typically system RAM, but fast SSDs are also used. Of course, predicting the future is difficult so no cache algorithm is perfect. Thankfully, even a moderately-accurate prediction rate will improve the user's apparent performance by a significant degree. The algorithm's prediction accuracy is called the "cache hit rate" and is represented as the percent of incoming data requests that are found in the cache versus those that are not (uncached reads are called "cache misses"). The cache hit rate of a given algorithm will greatly depend on the workload it's supporting: one workload may have a 95% cache hit rate on a given algorithm while a different workload might have a 2% cache hit rate.
The least recently used (LRU) algorithm is an example of a very simple cache algorithm. It goes like this:
- When a user reads some data, the cache stores a copy of that data in anticipation of future re-use.
- New data is added at the "top" of the cache and everything else gets bumped down.
- Once the cache fills up, the oldest item (the "least recently used" item) gets evicted from the bottom of the list to make room for the new incoming stuff.
- If data is re-read, it moves back to the top of the cache list.
Despite how simple LRU is, it does a pretty good job and is still popular today for basic applications. As we said before, even a modest cache hit rate of 5-10% will provide a decent performance boost to the user. This big boost for a seemingly paltry cache hit rate is largely due to how much slower hard disks are when compared to RAM. "Speed" in this context refers to the storage medium's latency, or how long it takes to fetch data after it receives a request. Modern DDR4 and DDR5 memory typically has a latency of 10 to 20 nanoseconds. Again, that's the delay between when the RAM module receives the read request and when the first chunk of data is available. 7200 RPM hard disks on the other hand have a typical latency of 10 to 15 milliseconds.
It's pretty difficult to wrap one's head around just how different these values are because we don't commonly deal in nanoseconds and milliseconds. To help understand just how slow hard drives really are, it's helpful to step through a thought experiment where we stretch time by a factor of 3 billion. In this expanded time scale, a 3GHz CPU would complete a single instruction every second. This lets us step into the perspective of the CPU which is waiting for data to be delivered by various types of storage. We can see these different types of storage listed below:
| Storage Type | Slowed Time Scale | Real Time Scale |
| Single CPU Instruction (at 3 GHz) | 1 second | 0.3 nSec |
| Registers (storage for active instructions) | 1 to 3 seconds | 0.3 to 1 nSec |
| Level 1 Cache (on-CPU cache) | 2 to 8 seconds | 0.7 to 3 nSec |
| Level 2 Cache (off-CPU but still on chip) | 5 to 12 seconds | 2 to 4 nSec |
| Main System Memory (RAM) | 30 to 60 seconds | 10 to 20 nSec |
| Intel Optane SSD | 6 to 15 hours | 10 to 15 uSec |
| NVMe SSD | 3 to 11 days | 100 to 200 uSec |
| SAS/SATA SSD | 69 to 105 days | 2 to 3 mSec |
| 15K RPM HDD | 105 to 210 days | 3 to 6 mSec |
| 10K RPM HDD | 243 to 315 days | 8 to 9 mSec |
| 7.2K RPM HDD | 315 to 525 days | 10 to 15 mSec |
| 5.4K RPM HDD | 525 to 700 days | 15 to 20 mSec |
| 3.5" Floppy Disk | 23.75 years!! | 250 mSec |
In this time scale, we can see that system RAM is still pretty snappy taking between 30 and 60 seconds to get data ready for us. A 7200 RPM hard drive on the other hand is slow to the point of being almost comical: the CPU may have to wait well over a year for the HDD to respond to a request.
To further drive the point home, imagine you want a slice of pizza. RAM access is like walking to the fridge, grabbing a slice and microwaving it for 30 seconds. Hard drive access is like walking from California to New York, buying a slice, and then walking all the way back to California before eating it. With that in mind, let's take a look at the adaptive replacement cache and see how many cross-country trips we can avoid (or how we can efficiently fit more pizza in the fridge).
The ARC
The adaptive replacement cache (commonly called the "ARC", pronounced just like Noah's famous boat) builds on the LRU strategy covered above in several ways. Perhaps most importantly, it adds a second list to track frequently-used blocks. Instead of the frankly unintuitive "least recently used" and "least frequently used" labels computer science at large has assigned to these two caching strategies, ZFS refers to them simply as the "recently used" and "frequently used" lists; those are the labels we'll use here as well. The "adaptive" part of the "adaptive replacement cache" comes from the algorithm's ability to reduce the size of the recently-used list to increase the size of the frequently-used list or vice versa.
We'll step through the journey a block takes as it goes through the various parts of the ARC below. You can follow along visually with the slides here:
The first time a block is read or written, a full copy of that data block gets entered into the ARC's recently-used list. This block might contain a portion of a movie you're watching, a photo you're editing, or data for a website your system is hosting. It's important to emphasize that ZFS enters both outgoing reads and incoming writes to the ARC. As more blocks get entered into the recently-used list, our block gets pushed down in the list. If our block is read a second time, it gets moved out of the recently-used list and is placed on top of the frequently-used list. Naturally, the frequently-used list doesn't fill as quickly as the recently-used list, but as it does, our block is pushed down lower in that list as well. If our block is read a third time, it moves back to the top of the frequently-used list (as it does for all subsequent accesses while the block is still tracked by the ARC).
The ARC starts to get more interesting as blocks are evicted from the recently- and frequently-used lists. In addition to these two primary cache lists, the ARC also keeps two "ghost" lists: one paired to the recently-used list and one paired to the frequently-used list. As blocks are evicted from the main recently- and frequently-used lists, they get tracked by the respective ghost lists. The ghost list entries don't contain the block's actual data, rather they track each block by reference, basically keeping a unique signature of each block on file. The ARC uses these ghost lists to adjust the relative sizes of the two primary lists. The ARC might start out with its total space being equally divided between the recently- and frequently-used lists but will start to adapt itself based on the user's data access patterns.
For example, if the block we were tracking above was eventually evicted from the frequently-used list, the actual data in that block is erased from the ARC but ZFS still puts a unique identifier for our block in the frequently-used ghost list. As with all the other ARC lists, newer entries in the frequently-used ghost list push down our block's entry (which again, only contains a unique ID of the block, not its actual data). If our block gets read again before it falls out of the ghost list, the ARC knows we evicted it from the frequently-used list too hastily. The ARC attempts to adjust itself to avoid this kind of miss in the future: instead of a 50/50 split between the recently- and frequently-used lists, it shifts the target balance a bit so it's maybe 48/52 in favor of the frequently-used list. The system then reads the data for our block from the disk, serves it up to the user and puts it at the top of the now slightly larger frequently-used list in the ARC. Because we are growing the frequently-used list at the expense of the recently-used list, when our block is placed at the top of the frequently-used list, the ARC actually evicts a block from the recently-used list to make room. It will continue to evict blocks from the opposite list until the ARC hits its target 48/52 balance.
As we mentioned above, the recently-used list has a ghost list as well. Hits on the recently-used ghost list will bias the ARC's total size towards the recently-used list. Maybe somewhat unintuitively, hits on the recently-used ghost list get entered on the frequently-used list; it is after all a re-access of that block.
Academic discussions of the ARC usually refer to the recently-used and frequently-used lists as T1 and T2 while their respective ghost lists as B1 and B2.
Unless specifically set by administrators, the ARC is shared across all pools on a ZFS system.
The L2ARC
ZFS' level 2 ARC or "L2ARC" is a second tier of caching you can optionally add to a pool. Somewhat confusingly, the L2ARC does not use the ARC algorithm to manage its cache; instead it uses a simple ring buffer where the first data into the cache is the last data to be evicted from the cache. You can attach an L2ARC vdev (usually in a striped vdev layout) to any pool to expand its overall cache size. Ideally, you would use a very fast and high-endurance SSD for this purpose.
L2ARC isn't necessarily beneficial for every workload. If your workload isn't frequently re-using the same data over and over, L2ARC won't help performance very much. For example, if you run your system as a backup target that just gets data written to it all day long, an L2ARC will do virtually nothing to improve performance. You can read more about when to use an L2ARC in the hardware section of this guide.
Because all data in the L2ARC (and in the ARC for that matter) also exists on your pool, you will not experience any data loss in the event of an L2ARC drive failure. For this reason, there really is no reason to mirror L2ARC drives in ZFS. If you have multiple L2ARC drives to use on a single pool, they'll be added as simple striped vdevs so you get the combined space of all the drives.
Every block stored in the system's L2ARC needs a small entry in a table in main memory. On the current version of OpenZFS, each of these entries take up 96 bytes in RAM. As we'll discuss later on in the ZFS tuning section, blocks are dynamically sized up to the recordsize value set on each dataset. The default recordsize value on ZFS is 128KiB.
Taking a fairly extreme example, let's assume the dataset's average block size is 32KiB. If we have 10TB of L2ARC attached to the pool, we can fit 305,175,781 of those 32KiB blocks in the L2ARC: (10TB * 1000^4) / (32 * 1024). Each of those blocks get an 96 byte entry in RAM, so we have ~27.3GiB of RAM dedicated to tracking L2ARC (305,175,781 * 96 / 1024^3). While that is a lot of RAM for L2ARC, unless the system only has 32GiB of memory, you should not see a dramatic performance decrease. A system with 64GiB of RAM should have the performance impact of the limited ARC size more than offset by the 10TB of L2ARC, especially if proper ARC size tuning is applied to the system.
If we set a higher recordsize value of 1MiB (as one might do if they're storing mostly large media files) and assume average block size is 512KiB, we can rerun the numbers with 10TB of L2ARC and find that we're only consuming a piddly 1.7GiB of RAM.
While the L2ARC adds a second tier of caching to your system, it does not implement a full auto-tiering strategy in ZFS. Auto-tiering is a data management strategy where frequently-accessed data is automatically moved off large, slow (and cheap) storage onto smaller, faster storage and then back down again after users are done with it. Such a strategy might employ more than just two tiers of storage and will potentially even push very cold data to tape and/or the cloud. The key difference between what ZFS is doing with the ARC and L2ARC and what auto-tiering is doing is in how it handles the data: the ZFS does caching which makes a copy of the data; tiering moves the data out of one storage tier and onto another. If an L2ARC device dies, all the data it holds will still be intact on the pool. If a storage tier fails on an auto-tiering system, all the data in that tier will need to be recovered.
ZFS does not support any auto-tiering mechanism and instead relies on the aggressive nature of the ARC algorithm to accelerate data access. An auto-tiering storage solution may be a better fit in some applications but the increased complexity often means increased cost and strange behavior in edge cases.
L2ARC is assigned to a specific pool on ZFS. Unless you partition out a single SSD, there is no way to share a single L2ARC disk between two pools. The official OpenZFS documentation recommends not partitioning devices and rather presenting a whole disk to ZFS, so if you run multiple pools and they all need L2ARC, plan to run multiple SSDs.
The ZIL, the SLOG, and Sync Writes
The ZIL and SLOG are arguably the most misunderstood concepts within ZFS. To understand the function of the ZIL and SLOG, we first need a high-level understanding of synchronous and asynchronous write calls.
Slides covering this topic can be found here:
Sync Writes
A synchronous write call is one where the system will wait to acknowledge the write until it's either been committed to stable, non-volatile storage (like an SSD or hard disk) or an error occurred. While it's waiting, the call is said to be "blocking"-- it blocks any other activity from happening on that thread until the write is safe. During that blocking period, the data only exists in memory and could be lost if the system crashes or experiences a sudden power loss. This in-memory data is sometimes called "in-flight" or "dirty" data. Once the data is safely stored on disk, the system will acknowledge the write and proceed to the next I/O call. Sync writes are slower but safer for critical data; if the writing application received an acknowledgement from the OS that the data was written, it can be confident that it's safely on disk. If it didn't get an acknowledgement, the application knows it needs to resend the data.
Async Writes
An asynchronous write call lives a little more dangerously. As soon as the write data is buffered in memory, the OS acknowledges it and lets the writing application continue running. That application will potentially send even more data to be written. The data in RAM will eventually be flushed out to disk but if the system crashes or loses power before that happens, the in-flight data will be lost. Once the system recovers, the writing application will need to assume that at least the last several seconds of data was lost and needs to be re-sent. This is typically a manual process as neither the OS nor the writing application will have reliable ways of tracking where in the flush-to-disk process the cutoff occurred. Async writes are faster but a bit riskier and shouldn't be used when handling critical data.
A goofy analogy to drive the point home: a sync write is sort of like when you were a kid and your parents would drop you off at a friend's house and wait in the driveway for you to get safely inside before they drove away. When your older brother or sister dropped you off, they would just drive away as soon as you were out of the car (that's an async write). Your parent's strategy takes more time but it keeps you (the in-flight data) safer.
Async and Sync Writes on ZFS
OpenZFS handles async writes in a pretty straightforward manner: they're aggregated in memory in a transaction group (txg) and flushed out after either enough data has been written to the txg or a timeout occurs. By default, the size threshold for the transaction group is either two percent of installed system memory or 819.2MiB, whichever is smaller. The default txg timeout interval is five seconds. Roughly every five seconds (or more frequently if you're writing a lot of data), the open transaction group is closed, it goes through a short quiescing ("kwee-ess-ing") phase where pending writes are wrapped up, and then gets synced to disk. OpenZFS lets administrators tune when and how these flushes occur to suit a specific workload; read more in the OpenZFS Tuning section below.
The way OpenZFS handles sync writes is a bit more complex. This is where we will introduce the concept of the ZFS intent log, or ZIL. As discussed above, sync writes need to fully land on non-volatile storage before the storage host acknowledges that the write completed and lets the writing application continue on with its work. Because OpenZFS is designed to aggregate incoming writes in memory (which is volatile storage), we need a little bit of stable storage to act as a temporary holding-area for in-flight sync writes. This little bit of stable storage to handle sync writes is called the ZFS intent log: it's a log of the data that ZFS intends to write out to the pool. The ZFS intent log is also referred to as the "ZIL".
When a sync write happens on ZFS, the data is simultaneously written to the txg in memory and to the ZIL. The system's memory is almost always going to be much faster than whatever storage we're using for the ZIL, so we end up having to wait around for the data to be completely written to the ZIL. Once the write to both memory and the ZIL have completed, ZFS acknowledges that it received the data and lets the writing application continue on its way. After either the transaction group fills up or its five second timer expires, the data will be flushed from memory (not from the ZIL, that's much slower) to its final destination on the storage pool. Once the data has hit the pool it can be dropped from the ZIL.
If the system loses power or otherwise crashes before the data is completely flushed from memory onto the pool, all of the in-flight data should still be safe on the ZIL. As the system is booting up and initializing ZFS, it will automatically check the ZIL for uncommitted writes. If it finds any, it performs a "ZIL replay" and finishes getting that data flushed out to disk. Note that this ZIL replay event is the only situation where the data will be read from the ZIL: during normal operation, data is written to the ZIL and then dropped. Unless ZFS is performing a ZIL replay, the writes out to the pool come from memory, not the ZIL.
Every ZFS pool has a ZIL. By default, ZFS carves out a small part of the storage pool to be used as a ZIL. Because the ZIL only holds a few seconds of write data, it doesn't need to be huge; a few gigabytes is usually more than enough. If the disks that comprise the pool are sufficiently fast (e.g., high performance SSDs), the pool shouldn't noticeably bog down under heavy sync write activity. Even with a pool made up of very fast high-performance SSDs, ZFS' use of the ZIL a sync write scratch space helps improve performance and reduce write latency. The process of flushing transaction groups out to disks can take multiple seconds, so if ZFS just wrote all sync writes directly to the pool, you would see terrible write latency. The transaction group mechanism also reduces fragmentation by aggregating a bunch of tiny writes into one large one; if each sync write was individually flushed out to the pool, the disks would quickly become fragmented beyond usability.
While SSDs can usually keep up with the random write workload imposed by the ZIL, a pool of hard disks can quickly become overwhelmed by all those individual tiny writes. Heavy sync writes to a hard-disk based ZIL can spike latency to the point where the storage is nearly unusable. To avoid this, ZFS provides a way to use a separate device for the ZFS intent log; this is commonly referred to as the SLOG (separate log) device or Log vdev.
If you attach a SLOG to a ZFS pool, it will prioritize it for ZIL use over the primary pool disks. ZFS still carves out a bit of space on the main pool as a backup ZIL in case the SLOG device fails, but you should expect all sync writes to run through the SLOG instead of the pool disks.
In a very old version of OpenZFS, a SLOG failure could often result in major data loss on the pool. Because of this, OpenZFS admins would often mirror their SLOG devices. That potential for major data loss has long been patched; for data loss to occur, the system would have to experience a Log vdev failure and lose power or have memory fail within a few seconds of each other. In the very rare event that both of these happen almost simultaneously, you will lose the uncommitted or in-flight write data. For some use cases, this remote risk is still sufficiently scary that it makes sense to mirror the SLOG, but for the vast majority of use cases, using a single high-quality SSD for a SLOG is plenty safe.
ZFS has the ability to lie to clients and to its underlying storage about sync and async writes. Each dataset has a special setting called the "sync" setting. By default, the value for this setting is "standard". When a dataset is set to "sync=standard", it will behave as we described above: async writes get buffered in RAM, sync writes go to RAM and the ZIL. In some cases, this may not be desired behavior, so ZFS also allows administrators to set "sync=always" and "sync=disabled". If you set "sync=always", ZFS will treat all incoming writes to that dataset as if they were sync writes, even if the writing application is sending them as async. This will likely slow down write performance to that dataset but it will ensure the data stays intact through a crash or reboot. Alternatively, admins can set "sync=disabled" on a dataset and all incoming data will be treated as async. This will likely speed up performance (assuming you had any sync writes to that dataset in the first place) at the expense of data safety. If you're unsure how to set this value, you should leave it as "sync=standard" for file-based workloads (i.e., SMB and NFS); losing a few seconds of data may not sound like a big deal but you can potentially have file corruption due to early truncation. iSCSI workloads supporting virtualization workloads will benefit from "sync=always" because iSCSI initiators can't replay lost writes like a file share client can.
Because the SLOG is used to protect important data from sudden power failures, it's important that the SLOG drive correctly reports cache flush events and ideally is power-loss protected. Some cheaper consumer-grade SSDs use volatile DRAM for caching to improve random write performance and may not accurately report when this DRAM cache is successfully flushed. Such drives may lose recently-written data if they experience a sudden power failure; this obviously defeats the entire purpose of a SLOG: you would be better off not using the SLOG in the first place or setting "sync=disabled" if data integrity isn't critical to your application. These cheaper SSDs usually have pretty bad random write performance which alone makes them a poor choice as a SLOG drive.
Pool Performance with ZIL/SLOG
It's also important to understand what a ZIL/SLOG is not: it is not (strictly speaking) a write cache that aggregates incoming writes before they're flushed to disk. As we discussed above, ZFS already does that using the transaction groups, but it gets flushed every few seconds. Because of these frequent flushes, sustained sequential writes to a ZFS pool will end up being throttled to the sequential write speed of the underlying disks. ZFS does not have a native mechanism to buffer minutes or hours worth of incoming writes before moving them to slower storage.
Just as there are common misconceptions about the function of the ZFS ZIL and SLOG, there are common misconceptions about the performance benefits of adding a SLOG to a ZFS pool. A SLOG is only beneficial to performance if the system if the pool will be handling sync writes (or you've set "sync=always") and the SLOG is sufficiently faster than the underlying pool disks. A SLOG will never improve performance beyond what it would be by setting "sync=disabled". Even if you had a SLOG that was somehow faster than your system's memory, you would still have to wait for the data to hit that memory before the write was acknowledged.
If you use the same type of SSD for both your pool and your SLOG, you could actually hurt performance. Without a SLOG, the ZIL will be evenly split between all the SSDs in your pool and should have more available performance than a single SSD SLOG device.
If you use a SLOG on an SSD pool, it needs to be significantly faster to provide a tangible benefit to performance. iX has done extensive testing with a TLC SAS SSD-based pool and an NVMe-based SLOG and found that the performance benefits of such a setup are almost negligible, certainly not enough to justify the considerable expense of an extra NVMe drive. If you have access to even faster storage (like NVDIMMs), they are sufficiently fast to make a difference on SSD pools.
When do I need a SLOG on TrueNAS?
A SLOG is only needed on ZFS if the system is handling sync writes (or you've manually set "sync=always"). Not all applications running on TrueNAS will generate sync writes. Specifically, the SMB server on TrueNAS (Samba) will write everything async. This means that if you are only running SMB on TrueNAS, you will not see any performance benefit by adding a SLOG to the pool (again, unless you've changed the sync settings).
By default, NFS v3 and v4 both write everything 100% synchronously. This means that if you are running any NFS on your system and your application is even mildly performance sensitive, you should strongly consider using a SLOG.
iSCSI and S3 will both generate some sync writes so a SLOG is advisable but not strictly necessary if performance isn't a concern.
There are other applications within TrueNAS that may occasionally write out data synchronously but the above sharing protocols are the most common. You can check if your system is generating sync writes by running zilstat -p $pool_name and watching the output for a while. You can also run gstat -p to check if your SLOG device is actually receiving any data.
Like the L2ARC, the SLOG is assigned to a specific pool on ZFS. Unless you partition out a single SSD, there is no way to share a single SLOG disk between two pools. The official OpenZFS documentation recommends not partitioning devices and rather presenting a whole disk to ZFS, so if you run multiple pools and they all need L2ARC, plan to run multiple SSDs.
Compression and Deduplication
The IT world is on a never-ending quest to make their finite resources more efficient and storage is no exception. Compression and deduplication are two of the most common data-reduction strategies and OpenZFS supports both. There are important things to be aware of when working with compression and dedup (especially with dedup) so read on to learn more.
Compression
ZFS supports a wide variety of inline compression algorithms to reduce your data's on-disk footprint. Inline compression (as opposed to a post-process compression) means that the compression process happens between when the data is received by the system and when it hits the disk. Not all data will be compressible; media and office document files are usually pre-compressed so ZFS won't be able to squeeze anything extra out of them. VM disk image files, databases, and large text repositories are usually very compressible. The effectiveness of compression is expressed as a "compression ratio" that compares the data's compressed size to its original size. If a 100GiB file gets compressed down to 50GiB, this would be a 2x compression ratio. Compressible data on ZFS will usually achieve somewhere between 1.3x and 1.8x compression. Incompressible data will have a ratio of 1.0x.
Most users will be familiar with how long it can take to unzip large files and so would naturally expect enabling compression in ZFS to come with a performance hit. Somewhat counterintuitively, enabling compression on ZFS can often lead to a performance boost when dealing with compressible data. Modern CPUs are so incredibly powerful that they'll usually have a fair amount of idle time even during peak system load. On most ZFS systems, the total disk throughput will be a bottleneck well before CPU becomes a bottleneck. By using a bit of extra CPU time to squeeze data down, ZFS can increase the effective pool speed. We can illustrate this with a simple example: we have a pool that is capable of handling 1GiB/sec reads and writes and we want to write a 100GiB file to that pool. The file has a 2x compression ratio, so instead of taking 100 seconds to write the file, it only takes 50, effectively making the write performance of the pool seem like 2GiB/sec. Reads work the same way: the 100GiB file only takes 50GiB worth of disk reads to fetch, so we can do that in 50 seconds. Compression is effectively boosting our performance by a factor equal to the achieved compression ratio.
If the CPU is actually a bottleneck, compression is still usually a net win for performance. You probably won't see performance boosted by the compression ratio but it should still be better than if compression was totally disabled.
ZFS supports a bunch of different compression algorithms including lz4, zstd, gzip, zle, and lzjb. Many of these algorithms support the ability to tune between compression speed and effectiveness. The default algorithm is lz4 and it's preferred in most cases; it provides an excellent balance between performance and effectiveness. The lz4 algorithm also has a nifty early-abort mechanism that will cause it to skip over blocks that are not sufficiently compressible. This avoids burning CPU time to achieve a 1.0001x compression ratio on virtually incompressible blocks. For this reason, it's highly recommended to leave compression enabled on all datasets and zvols even if you're storing mostly incompressible data. If you know for a fact that your data will be totally and utterly incompressible, go ahead and disable compression, but don't expect overall CPU usage or system performance to change dramatically.
OpenZFS recently added the zstd algorithm to its compression options. This algorithm supports compression speed tuning values. These values are represented as different compression options labeled "zstd-1" through "zstd-19" and "zstd-fast-1" through "zstd-fast-1000". Higher numbers will achieve marginally better compression ratios but much lower performance. With zstd-5, you might get a 1.28x compression ratio compared to 1.30x with zstd-19 but zstd-19 will run 4-5x slower than zstd-5.
Compared to lz4, zstd is generally slower and gets slightly better compression ratios. If your workload is at all performance sensitive, you should stick with lz4. If you want to squeeze every last bit of storage out of your system and you're ok with a bit of a performance penalty, you might consider using a lower-level zstd. The other compression algorithm options OpenZFS offers should really never be used outside of testing.
Deduplication
ZFS supports inline deduplication (or "dedup") to further reduce your data's on-disk footprint. As with compression, ZFS does dedup inline meaning all processing needs to happen between when ZFS gets the new data and when it's committed out to disk.
ZFS implements dedup using a massive hash table (called the dedup table) that stores a unique ID (called a hash) for every single block in the deduplicated dataset. As new blocks are written to the dataset, ZFS computes the hash for the new block and checks to see if it already exists in the dedup table (or DDT). If it does, instead of storing that block a second time, it stores a small reference back to where it can find the original copy of the data. This scenario where there is a match in the dedup table is referred to as a "dedup hit". A "dedup miss" is when the incoming block is not in the dedup table and needs to be written out to disk. After it's written, the dedup table would be updated to include a hash of the new block and its on-disk address.
Each entry in the dedup table will be between 300 and 900 bytes in size and every unique block in the dataset gets an entry. If you have 50TiB of unique data stored in 128KiB blocks, that means you have 419,430,400 unique blocks on the dataset. On the low end, your dedup table will be ~117.2 GiB and on the high end, it will be ~351.6 GiB. The dedup table gets referenced every time there is a read or write operation to the dataset, so unless it fits entirely in memory, performance will be very low.
In practice, even if the dedup table fits entirely in RAM, there are a lot of extra steps in every I/O operation when dedup is enabled. Dedup table misses are particularly painful because they require extra I/O to update the DDT. Dedup is also very CPU intensive as there is a lot of extra hashing involved with every write operation. Expect scrubs and resilvers of pools supporting dedup-enabled datasets to run slow and take up a lot of CPU time.
The default checksum hash algorithm used to verify pool-wide data integrity on OpenZFS, fletcher4, was designed to be simpler and lighter on the CPU than other algorithms. Because the algorithm omits some steps and features to maintain simplicity, fletcher4 is not considered cryptographically secure, meaning the chance of a hash collision (where two different pieces of input data produce the same hash output) are non-negligible. For this reason, when you enable dedup on a ZFS dataset, the system will automatically switch the checksum algorithm on that dataset from fletcher4 to SHA-256. The OpenZFS documentation states that this choice of SHA-256 might change in the future because SHA-512 is actually much faster on modern 64-bit CPUs. In other words, if you're running a 64 bit CPU and plan to use dedup, make sure you switch the checksum algorithm on your dataset to SHA-512. If you're running a 32 bit CPU, enabling dedup will turn your processor back into a pile of useless sand.
It is possible to add SSDs to a pool to host the DDT using the "special vdev" function recently added to OpenZFS. SSDs supporting the dedup table should be able to handle many hundreds of thousands of 4K IOPS to keep up with system demand. You won't avoid the big performance hit of dedup by storing the DDTs on SSDs but you can at least avoid having to deploy hundreds of terabytes of RAM in your system. More details and recommendations on dedup can be found in the official TrueNAS docs.
If you have some data already on ZFS and you're interested to know how well it will dedup, there is a command you can run to simulate the process and present a concise report of the potential space savings. Run zdb -U /data/zfs/zpool.cache -S $pool_name on your pool but know that this can take hours or even several days to return and system performance may be degraded while it's running.
In case it wasn't obvious from the information above, enabling dedup in TrueNAS is strongly discouraged. There are almost always far more cost effective ways to store the additional, duplicated data (including just running more disks). Once you've enabled dedup on a dataset, it's not trivial to disable it: the data needs to be moved out of the dedup-enabled dataset and that dataset needs to be destroyed. If your workload needs even a moderate level of performance, dedup will likely result in unacceptably low performance. Because dedup "misses" are so expensive, the performance impact will increase as the achieved dedup ratio drops. iXsystems generally does not recommend even considering dedup unless the dedup ratio is expected to be greater than 5x.
OpenZFS Encryption
OpenZFS recently added native encryption support to protect at-rest data. TrueNAS also supports self-encrypting drives (SEDs) but we'll cover those in another section.
TrueNAS provides the ability to encrypt the root-level dataset during pool creation so everything on the pool is encrypted by default. Alternatively, you can encrypt individual datasets as they're created.
ZFS encryption can be configured per-dataset, meaning you can have one dataset with encryption enabled to store sensitive information on the same pool as another dataset without any encryption. Encryption can only be enabled during dataset creation, so if you have an existing dataset that needs to be encrypted, you'll need to make a new dataset with encryption enabled and migrate data into it. The same is true (in reverse) if you need to disable encryption on a dataset.
When configuring encryption in TrueNAS, there are several cipher algorithms to choose from but there is really no reason to choose anything but the default AES-256-GCM. When creating an encrypted dataset, you'll need to either provide or create an encryption key; this key can optionally be password protected. By default, TrueNAS will manage the encryption key internally but TrueNAS Enterprise also supports KMIP.
Many full-disk encryption schemes end up rendering data compression useless. This is because all filesystem compression relies on patterns to reduce the data footprint and encryption makes the data effectively random and patternless. Thankfully, this isn't the case with OpenZFS encryption: the compression step takes place before the encryption step, so you can take advantage of both features on the same dataset.
It's important to emphasize that ZFS is only implementing encryption at rest. It's meant to prevent data loss if the hardware is stolen or otherwise compromised. With encryption at rest, you can discard failed drives safely; someone that picks it up out of the trash won't be able to recover any useful data from it. It does not (by itself) offer any protection against ransomware or malicious individuals already on your network. Once the system is booted and the encrypted dataset(s) are unlocked, users do not need the encryption key to access any of the data.
Encryption in ZFS does come with a slight CPU penalty. In testing, iX has observed up to a ~15% performance impact on smaller 6-core CPUs. This impact is only really felt if the CPU is otherwise maxed out. If you do have enough spare CPU cycles to handle the encryption, the performance impact will be negligible. The performance impact will only be felt on reads from and writes to encrypted datasets, so you can potentially minimize the hit by splitting up your data and putting only sensitive files in encrypted datasets. If you plan to use ZFS encryption, make sure your CPU supports the AES-NI instruction set, otherwise the performance impact will be much larger.
If you have deduplication enabled on a dataset, ZFS' dedup table will not be encrypted with native OpenZFS encryption. Generally, this shouldn't be too big of a deal for most applications. If your application needs dedup and encryption (including the dedup table), consider using SEDs or running without dedup.
Checksums and Scrubs
ZFS forms a Merkle tree structure to ensure top-to-bottom data integrity (this is a fancy way of saying blocks store checksums of their children in a big block tree structure). When new data is written to the pool, ZFS automatically checksums that data and all associated metadata for later reference. The next time that data is read, ZFS recalculates the checksum of the on-disk data to confirm it still matches the checksum on file (i.e., the data has not changed since it was originally written). Usually, the on-disk data has not changed so the checksum still matches and ZFS returns the data to whatever application requested it.
If the data has changed (even by a single bit), the checksum will not match. ZFS will attempt to recover the data either by reading from another spot on disk, from another disk in the mirror, or by reconstructing the data using RAIDZ parity. If it successfully recovers the data, it repairs the original location, makes a note of the error, and continues on. If enough of these errors accumulate on a single disk, ZFS will consider that disk faulted and "resilver" (ZFS' term for rebuilding a vdev) in a hot spare if one is attached to the pool.
This process works well to ensure the integrity of data that is frequently accessed, but if you have lots of data that is almost never accessed (say, for a deep data archive), it may be vulnerable to silent data corruption. Discovering this corruption during the resilver process may be catastrophic to the pool. To avoid this situation, ZFS lets administrators schedule automatic data "scrubs". During a scrub, ZFS will step through all data and metadata on a pool and confirm that the checksums still match. As during a routine data read, if anything on-disk is amiss, ZFS will attempt to automatically repair it.
TrueNAS automatically schedules scrubs every 35 days but you're free to change that interval if needed. Scrubs can be quite resource intensive and will cause disk and CPU utilization to run at or near 100% for a while. Scrubs of larger pools can take a day or more and because they are so resource intensive, other workloads on the pool may slow down. Scrubs can be prioritized down so they take longer but cause less of an impact to other workloads on the pool. Usually, you'll want to let the scrub run at full speed and get it over with but if that isn't an option, consider deprioritizing it.
Modifying Pools, Vdevs, and Datasets
Once you've created your pool and some datasets, you may want to make changes after living with your storage for a while. Certain changes are allowed to pools, vdevs, and datasets after they're created, other changes are not allowed.
Pool Changes
These are changes you're allowed to do to a pool after it has been created:
- Add vdevs to the pool
- Add a SLOG to the pool
- Remove a SLOG from the pool
- Add an L2ARC to the pool
- Remove an L2ARC from the pool
- Rename a pool (pool needs to be unmounted and remounted to rename it)
- Remove a mirrored vdev from the pool (only if all data vdevs are also mirrors)
- Destroy the pool
These changes are NOT allowed after a pool has been created:
- Change the ashift value used for the vdevs on the pool
- Remove a RAIDZ or dRAID vdev from the pool (or a mirrored vdev if you're mixing vdev types)
That last one is very important. If you mess up and add the wrong RAIDZ vdev configuration to a pool, the only way to undo it is to destroy the pool and recreate it.
Vdev Changes
These are changes you're allowed to do to a vdev after it has been created:
- Add a drive to a mirrored vdev (e.g., go from 2-way mirror to 3-way mirror)
- Remove a drive from a mirrored vdev (e.g., go from 3-way mirror back to 2-way)
- Break a mirrored vdev (e.g., go from a 2-way mirror to a striped vdev)
- Replace individual disks in a vdev with disks of the same or large capacity
- Destroy all the vdevs (by destroying the pool)
These changes are NOT allowed after a vdev has been created:
- Change the configuration of a RAIDZ or dRAID vdev (e.g., go from RAIDZ1 to RAIDZ2)
- Add drives to a RAIDZ1, Z2, Z3, or dRAID vdev
- Remove drives from a RAIDZ1, Z2, Z3, or dRAID vdev
- Add distributed spares to a dRAID vdev
- Remove distributed spares from a dRAID vdev
- Replace individual disks in a vdev with disks of a smaller capacity
- Change the ashift value of a vdev
Dataset Changes
These are changes you're allowed to do to a dataset or zvol after it has been created:
- Add a dataset or zvol as a child of another dataset
- Change most dataset properties (note, changes sometimes only impact newly-written data)
- Rename a dataset or zvol (not available in TrueNAS UI, requires CLI and
zfs renameand might break existing shares) - Change zvol sparse settings (refreservation=auto for thick, refreservation=none for thin)
- Destroy a dataset or zvol
These changes are NOT allowed after a dataset or zvol has been created:
- Change dataset case sensitivity and unicode settings
- Change a zvol's volblocksize
- Enable or disable encryption
- Add a file system dataset as a child under a zvol
OpenZFS Distributed RAID (dRAID)
dRAID, added to OpenZFS in v2.1.0 and TrueNAS in SCALE v23.10.0 (Cobia), is a variant of RAIDZ that distributes hot spare drive space throughout the vdev. While a traditional RAIDZ pool can make use of dedicated hot spares to fill in for any failed disks, dRAID allows administrators to shuffle the sectors of those hot spare disks into the rest of the vdev thereby enabling much faster recovery from failure.
After a RAIDZ pool experiences a drive failure, ZFS selects one of the pool's assigned hot spares and begins the resilver process. The surviving disks in the faulted vdev experience a very heavy, sustained read load and the target hot spare experiences a heavy write load. Meanwhile, the rest of the drives in the pool (the drives in the non-faulted vdevs) do not contribute to the resilver process. Because of this imbalanced load on the pool, RAIDZ pool resilvers can potentially take days (or even weeks) to complete.
By contrast, after a dRAID pool experiences a drive failure, all of the disks in the faulted dRAID vdev contribute to the resilver process because all of the disks in the dRAID vdev contain hot spare space as well as data and parity information. With all of the drives more evenly sharing the recovery load, dRAID pools can resilver and return to full redundancy much faster than traditional RAIDZ pools. The chart below (from the official OpenZFS docs) shows the rebuild time of a traditional RAIDZ-based pool versus several dRAID configurations:
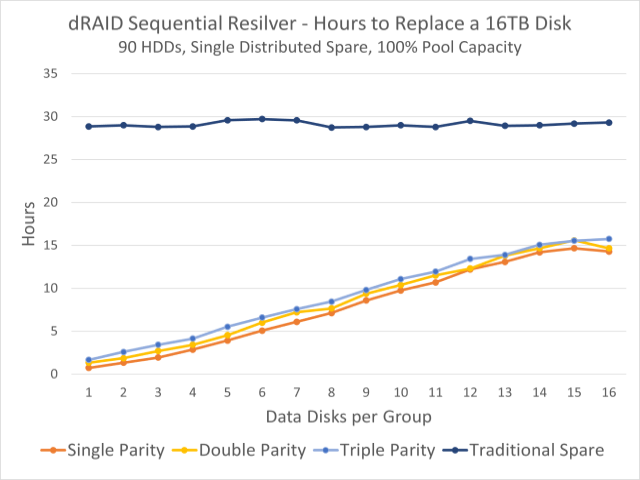
dRAID represents something of a paradigm shift for ZFS administrators familiar with RAIDZ. The distributed RAID technology introduces a number of new terms and concepts and can be confusing and intimidating for new users. We'll outline everything you need to know in order to get started here and, for those interested, we will also dive into the weeds to see how this new vdev layout works.
dRAID Basics
If you create a new RAIDZ (Z1, Z2, or Z3) pool with multiple vdevs and attach a hot spare or two to that pool, ZFS effectively silos a given vdev's data to the disks that comprise that vdev. For example, the set of disks that make up vdev #2 will hold some data and some parity protecting that data. Obviously, this vdev #2 will not have any parity data from any other vdevs in the pool. Hot spares also do their own thing: they don't store anything useful and they just sit idle until they're needed. Parity data within a given vdev is naturally distributed throughout that vdev's disks by nature of the dynamic block size system RAIDZ employs; RAIDZ does not dedicate a particular disk (or set of disks) to hold parity data and does not neatly barber-pole the parity data across the disk like more traditional RAID systems do.
dRAID effectively combines all of the functions outlined above into a single, large vdev. (You can still have multiple dRAID vdevs in a pool; we'll discuss that below.) Within a dRAID vdev, you'll likely find multiple sets of data sectors along with the parity sectors protecting that data. You'll also find the spares themselves; in dRAID terminology, these hot spares that live "inside" the vdev are called virtual hot spares or distributed hot spares. A given set of user data and its accompanying parity information are referred to as a redundancy group. The redundancy group in dRAID is roughly equivalent to a RAIDZ vdev (there are important differences; we'll cover them below) and we usually expect to see multiple redundancy groups inside a single dRAID vdev.
Because a single dRAID vdev can have multiple redundancy groups (again, think of a single pool with multiple RAIDZ vdevs), dRAID vdevs can be much wider than RAIDZ vdevs and still enjoy the same level of redundancy. The maximum number of disks you can have in a dRAID vdev is 255. This means that if you have a pool with more than 255 disks and you want to use dRAID, you'll have multiple vdevs. There are valid reasons to deploy smaller vdevs even if you have more than 255 disks: you may want one dRAID vdev per 60-bay JBOD, for example. The number of disks in the dRAID vdev is referred to as the number of children.
Just like with RAIDZ, dRAID lets us choose if we want single, double, or triple parity protection on each of our redundancy groups. When creating a dRAID pool, administrators will also specify the number of data disks per redundancy group (which can technically be one but should really be at least one more than the parity level) and the number of virtual spares to mix into the vdev.
Somewhat confusingly, dRAID lets redundancy groups span rows. Consider a dRAID vdev with 24 disks, a parity level of 2, and 6 data disks per redundancy group. For now, we won't use any spares so things line up nicely: on each row of 24 disks, we can fit exactly 3 redundancy groups:
(2 parity + 6 data) / 24 children = 3 redundancy groups
The layout (before it's shuffled) is shown below:
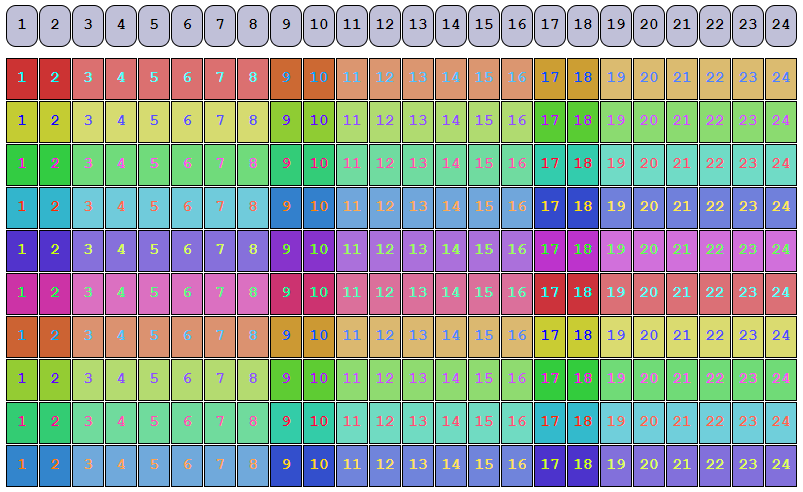
In this image, the darker boxes represent parity information and the paler boxes are user data. Each set of 8 similarly-colored boxes is a redundancy group. The purple boxes as the top of the diagram are labels showing the physical disks.
Although it's counter-intuitive, we can actually add a spare to this dRAID vdev without increasing the number of child disks. The first row will have two full and one partial redundancy groups (as well as one spare): the third redundancy group will partially spill over into the second row. The layout (again, before it's shuffled) is shown below:

Because the virtual spare (represented here by the white blocks) does not need to be confined to a single physical disk, storage administrators have some additional freedom when designing dRAID layouts. This layout achieves the physical capacity of 17x disks almost as if we had 2x 6wZ2 vdevs, 1x 5wZ2 vdev, and a hot spare.
The dRAID notation is a bit cryptic, but once you understand the four variables at play, it starts to make sense. Again, the variables are the parity level (p), the number of data disks per redundancy group (d), the total number of child disks (c), and the total number of spares (s). The example above with 2 parity, 6 data, 24 children, and 1 spare would be annotated as:
draid2:6d:24c:1s
Because redundancy groups can span rows, the only real restriction here (other than those laid out above) is that the number of child disks must be at least as many as p+d+s. You can't, for example, have the following layout:
draid2:21d:24c:2s
Obviously, we can't fit 2 parity disks, 21 data disks, and 2 spare disks in 24 children and maintain double-parity protection on all the data. It then follows that the maximum number of virtual spares you can include in a dRAID vdev is c-(d+p). If we set d=1 in the 24-disk example above, we would be allowed up to 21 spare disks:
draid2:1d:24c:21s
If we try to include more than 21 spares, we won't have enough room for the single data disk and two parity disks in our 24-disk stripe.
dRAID Recovery Process
The primary objective of distributed RAID is to recover from a disk failure and return to full redundancy as quickly as possible. To that end, OpenZFS has created a new resilver process sequential resilver. You'll most commonly come across sequential resilvers in the context of dRAID, but you can also do a sequential resilver on mirrored vdevs.
Before diving into the sequential resilver, it will be helpful to review the traditional (or "healing") resilver. When a disk fails in a pool with RAIDZ or mirrored vdevs, the subsequent resilver process will scan a massive on-disk data structure called the block tree. Scanning this block tree is not a simple, sequential process; instead, we have to follow a long, complex series of block pointers all over the pool. A block here may point to a block way over on the other side of the platter, which in turn points to some other blocks somewhere else. Walking through the entire block tree in this fashion takes a long time but it allows us to verify the integrity of every bit of data on the pool as we're performing the operation; every block in ZFS contains a checksum of the blocks it points to further down the tree. Once the healing resilver has completed, we can be confident that our data is intact and corruption-free.
Obviously, the primary disadvantage of performing a full healing resilver is the extended time it can take to complete the procedure. During this time, our pool is highly vulnerable: subsequent disk failures could easily cause total data loss or, in the best case, drastically extend the period of pool vulnerability. dRAID aims to minimize that risk by minimizing the time that the pool is vulnerable to additional failures. This is where the sequential resilver comes in. As the name suggests, the sequential resilver simply scans all the allocated sections of all the disks in the vdev to perform the repair. Because the operations are not limited to block boundaries and because we're not bouncing all over the disk following block pointers, we can use much larger I/O's and complete the repair much faster. Of course, because we are not working our way through the block tree as in the healing resilver, we can not verify any block checksums during the sequential resilver.
Validating checksums is still a critical process of the recovery, so ZFS starts a scrub after the sequential resilver is complete. A scrub is basically the block-tree-walking, checksum-validating part of the healing resilver outlined above. As you might expect, a scrub of a dRAID pool can still take quite a long time to complete because it's doing all those small, random reads across the full block tree, but we're already back to full redundancy and can safely sustain additional disk failures as soon as the sequential resilver completes. It's worth noting that any blocks read by ZFS that have not yet been checksum-validated by the scrub will still automatically be checksum-validated as part of ZFS' normal read pipeline; we do not put ourselves at risk of serving corrupted data by delaying the checksum validation part of the resilver.
We've essentially broken the scrub into its two elements: the part that gets our disk redundancy back, and the part that takes a long time. A traditional resilver does both parts in parallel while the sequential scrub lets us do them in a sequence.
After the faulted disk is physically replaced, ZFS begins yet another new operation called a rebalancing. This process restores all the distributed spare space that was used up during the sequential resilver and validates checksums again. The rebalancing process is fundamentally just a normal, healing resilver, which we now have plenty of time to complete because the pool is no longer in a faulted state.
Other dRAID Considerations
As mentioned above, dRAID vdevs come with some important caveats that should be carefully considered before deploying it in a new pool. These caveats are discussed below:
- Unlike RAIDZ, dRAID does not support partial-stripe writes. Small writes to a dRAID vdev will be padded out with zeros to span a redundancy group. This means that on a dRAID vdev with d=8 and 4KiB disk sectors, the minimum allocation size to that vdev is 32KiB. Essentially, this is the price that needs to be paid in order to support sequential resilvers. Given that, administrators should ensure they set recordsize and volblocksize values appropriately. If your workload includes lots of small-block data, running it on dRAID will likely create a lot of wasted space (unless you use special allocation classes; see below).
- Because spare disks are distributed into the dRAID vdev, virtual spares can not be added after the vdev is created. This means that it is impossible to go from a
draid2:6d:24c:0sto adraid2:6d:24c:1swithout destroying the pool and recreating it. - Performance of a dRAID vdev should roughly match that of an equivalent RAIDZ pool: vdev IOPS will scale based on the quantity of redundancy groups per row and throughput will scale based on the quantity of data disks per row.
- Just as with RAIDZ, expansion of a dRAID pool requires the addition of one or more new vdev(s). Unlike RAIDZ, your dRAID vdev could have 100 or more disks in it. The ZFS best practice of using homogeneous vdevs in a pool still apply, meaning minimal expansion increments to a dRAID-based pool might be very large.
- If you are creating a dRAID-based pool with more than 255 disks, you'll need to use multiple vdevs. As above, adhering to best practices would mean keeping all vdevs alike, so rather than taking 300 disks and making one 255-wide vdev and one 45-wide vdev, consider either 2x 150-wide vdevs or 3x 100-wide vdevs.
- Administrators can still attach L2ARCs, SLOGs, and special allocation class ("fusion") vdevs to dRAID-based pools. Special allocation class vdevs were specifically designed to work with dRAID because they help to mitigate the poor efficiency and performance you might see when storing small blocks (particularly metadata blocks). Technically, you can also attach a normal hot spare to a dRAID pool but I honestly can not think of a reason why you would.
- Leaving resilver time aside, a dRAID-based pool will almost always be more susceptible to total pool failure than a comparable RAIDZ pool at a given parity level. This is because dRAID-based pools will almost always have wider vdevs than RAIDZ pools but still have per-vdev fault tolerance. As discussed above, a pool with 25x 10-wide RAIDZ2 vdevs can theoretically tolerate up to 50x total drive failures while a dRAID configuration with 250x children, double parity protection, and 8 data disks per redundancy group can only tolerate 2x total disk failures. Once we consider the shorter resilver time of dRAID vdevs, the pool reliability comparison becomes a lot more interesting. This is discussed more below.
- Although the concept of distributed RAID has existed in the enterprise storage industry for more than a decade, the ZFS implementation of dRAID is very new and has not been tested to the same extent that RAIDZ has. If your storage project has a very low risk tolerance, you may consider waiting for dRAID to be a bit more well-established.
When to use dRAID
Distributed RAID on ZFS is new enough that its suitable range of applications has not yet been fully explored. Given the caveats outlined above, there will be many situations where traditional RAIDZ vdevs make more sense than deploying dRAID. In general, I think dRAID will be in contention if you're working with a large quantity of hard disks (say 30+) and you would otherwise deploy 10-12 wide Z2/Z3 vdevs for bulk storage applications. Performance-wise, it won't be a good fit for any applications working primarily with small block I/O, so backing storage for VMware and databases should stay on mirrors or RAIDZ. If deployed on SSDs, dRAID may be a viable option for high-performance large-block workloads like video production and some HPC storage, but I would recommend thorough testing before putting such a configuration into production.
I've found the easiest way to approach the "when to dRAID?" question is to consider a given quantity of disks and to compare the capacity of those disks laid out in a few different RAIDZ and dRAID configurations. I built an application to graph characteristics of different RAID configurations to make this comparison process a bit easier; that tool is available here and will be referenced in the discussion below.
The graph below shows the capacity of several different RAIDZ2 and dRAID2 layouts with 100 1TB drives. The RAIDZ2 configurations include at least two hot spares and the dRAID2 configurations use two distributed spares and 100 children. The graphs show total pool capacity as we increase the width of the RAIDZ2 vdevs and increase the number of data disks in the dRAID layouts. We let both the RAIDZ2 vdev width and the quantity of dRAID data disks increase to 40.
On both datasets, we see an interesting sawtooth pattern emerge. On the RAIDZ2 dataset, this is due to the vdev width getting close to being divisible by the total quantity of disks and then overshooting that and leaving lots of spare disks. When the vdev width is 24, we end up with four vdevs and four spare drives. Increasing the vdev width to 25 leaves us with three vdevs and 25 spare drives (remember, we've specified a minimum of two hot spares, so four 25-wide Z2 with zero spares would be invalid here).
The sawtooth pattern on the dRAID dataset is caused by partial stripe writes being padded out to fill a full redundancy group. Both datasets assume the pools are filled with 128KiB blocks and are using ashift=12 (i.e., drives with 4KiB sectors). A 128KiB block written to a dRAID configuration with 16 data disks will fill exactly two redundancy groups (128KiB / 4KiB = 32 sectors, which explains why we see another big peak at d=32). If we have 31 data disks in each redundancy group, a 128KiB block will entirely fill one redundancy group and just a tiny bit of a second group; that second group will need to be padded out which massively cuts into storage efficiency.
We can mitigate how dramatic this sawtooth shape is on the dRAID curve by increasing the recordsize. To make a fair comparison, we'll increase the recordsize on both dRAID and RAIDZ2 to 1MiB:
Apparent usable capacity on both configurations has increased slightly with this change. The sawtooth pattern on the RAIDZ2 configuration set hasn't gone away because we've only changed our recordsize, not how many disks fit into a vdev. The dRAID line is a bit smoother now because we've reduced how much capacity is wasted by padding out partially-filled redundancy groups. A 1MiB block will fill 256 data sectors (1024KiB / 4KiB = 256). If we have 31 data disks in each redundancy group, we end up with eight full redundancy groups and one partially-filled group that needs to be padded out. We're still losing some usable space, but not nearly as much as before when the recordsize was 128KiB (one redundancy group with padding per eight groups full is much better than one group with padding for every one full).
We can clearly see that in most cases (especially the more "sane" cases where we limit the RAIDZ2 width to about 12 disks), dRAID eeks out a bit more capacity. As noted above, however, if we consider the pools' resilience against failure, the dRAID2 configurations look less attractive:
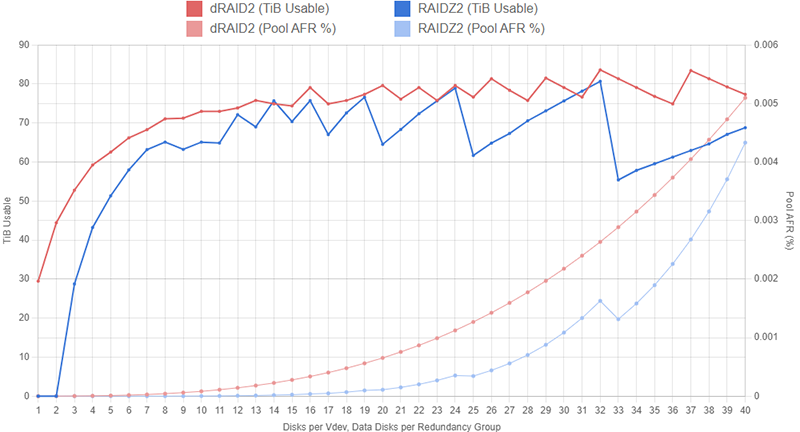
Because the dRAID vdev is so much wider and can still only tolerate up to two disk failures, it has a significantly higher chance of experiencing total failure when compared to the RAIDZ2 configurations. These annual failure rate (AFR) values assume the dRAID pool resilvers twice as fast as the RAIDZ pool for a given width.
By switching to dRAID3, we can actually drop the pool's AFR by a considerable amount while still maintaining high usable capacity. For the following graphs, we're going to limit the RAIDZ vdev width to 24 so it doesn't throw off the AFR axis scale too much.
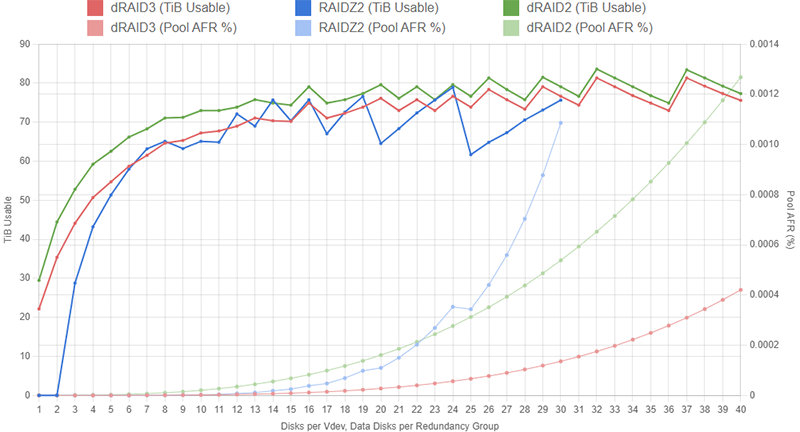
For reference, the dRAID2 configurations are shown here in green. The AFR of the dRAID configurations is considerably lower than the Z2 configurations across the board. As before, these AFR values assume the dRAID vdevs resilver twice as fast as the Z2 vdevs for a given width.
Even at d=16, the dRAID3 configuration has a roughly similar AFR to a 10-wide RAIDZ2 layout while offering more usable capacity. If you can stomach the lack of partial stripe write support and the large expansion increments, a dRAID3:16d:100c:2s pool may seem very appealing. Here's a closer look at just the Z2 and dRAID3 configurations confined to 16 disks:
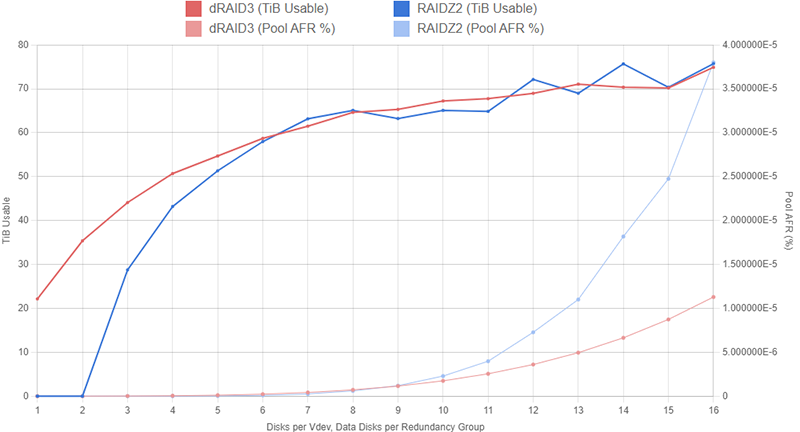
Before deploying this layout on brand new hardware, it should be noted that the pool AFR data on these graphs use a very simplistic model to predict resilver times and should not be taken as gospel. The model starts with an individual disk's AFR, usually somewhere between 0.5% and 5%. We then try to estimate the resilver time of the pool by multiplying the vdev's width (or the number of data drives in a dRAID config) by some scale factor. For the charts above, we assumed each data disk on a dRAID vdev would add 1.5 hours to the resilver time and each data disk on a RAIDZ vdev would add 3 hours to the resilver time (so a 12-wide RAIDZ2 vdev would take 30 hours to resilver and a dRAID vdev with d=12 would take 15 hours to resilver).
These 1.5 and 3 numbers are, at best, an educated guess based on observations and anecdotal reports. We can fiddle with these values a bit and the conclusions above will still hold, but if they deviate too much, things start to go off the rails. It's also unlikely that the relationship between vdev width (or data drive quantity) and resilver time is perfectly linear, but I don't have access to enough data to put together a better model.
You may also find that you can "split" the dRAID vdev in half to lower its apparent AFR. For example, if you compare 2x draid2:8d:50c:1s vdevs to 1x draid2:8d:100c:2s vdev, you'll see the 2x 50c version has a lower apparent AFR across the board (keeping the resilver times the same). In reality, the 100c configuration should resilver much faster because it has 100 total drives doing the resilver instead of only 50; this will bring the AFR curve for the two configurations much close to each other. I don't (yet) have data on how this scaling works exactly, but I'm curious to experiment with it a bit more.
If we had started out with 102 disks instead of an even 100, the RAIDZ2 configurations would have more capacity relative to the dRAID configurations because we can use (as an example) 10x 10wZ2 vdevs and still have our requisite two spares left. Here is a dRAID2, dRAID3, and RAIDZ2 configuration set with 102 drives instead of 100:
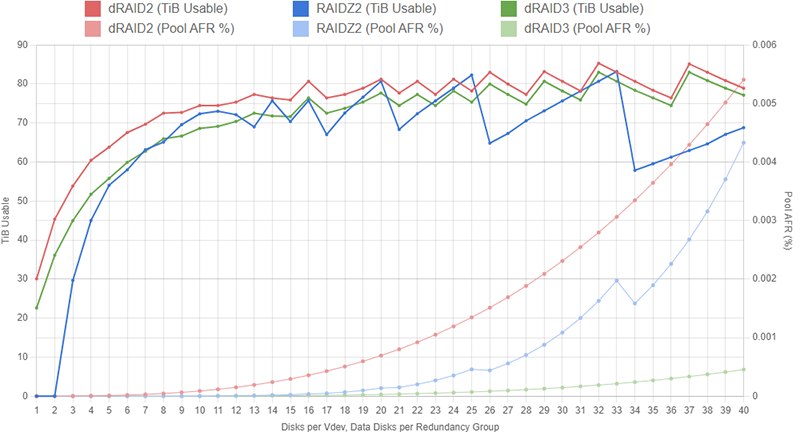
In cases where you have a nice round number of drives (like 60 or 100), dRAID may be preferable because it still lets you incorporate a spare without throwing the vdev width off too much. There is an option in the Y-Axis menu controls to show the number of spare drives for each layout; you'll want to validate that your layout is not leaving you with a huge excess of spare drives.
I would encourage you to explore this graph tool a bit for yourself using parameters that match your own situation. Start by plotting out a few different dRAID and RAIDZ configurations, try changing the parity value a bit, check how changing the recordsize impacts the results too. Layer on the pool AFR curve and see how changing rebuild times impacts the results. If you find a dRAID topology that offers more capacity than a sensible RAIDZ topology, you might also check out the relative performance curves. Once you've absorbed as much data as you can, you'll need to decide if that extra capacity is worth the dRAID tradeoffs and the little bit of uncertainty that comes with relying on relatively new technology.
If you're interested in a deeper, technical look at dRAID's internals, check out the ZFS Tuning & Internals section below.
OpenZFS Tuning & Internals
OpenZFS includes literally hundreds of parameters that can be tuned by admins to optimize its behavior for a given workload. Even beyond the basic pool and dataset options, OpenZFS includes 280 (at last count) module parameters that can be used to override its default behavior. Most of these should not be changed unless you want to experiment and/or break your system, but some of them can be useful in certain situations. We'll cover the important pool and dataset options as well as a few useful module parameters in this section.
Many dataset options in ZFS can be changed after the dataset has been created and even after it's had some data written to it. Some options once changed will only affect newly-written data. For example, if you create a dataset with lz4 compression set, write some data, then change the compression to zstd-5, the original lz4-compressed data will not automatically be converted over to zstd-5. Any newly-written data will use zstd-5 and if you move the old lz4-compressed data off the dataset and back on, it too will be zstd-5 compressed. We'll make note of any such dataset options that require data a rewrite.
Pool ashift
Before starting any other performance tuning, you should make sure ZFS is using block sizes that make sense for your physical media and for your workload. The pool's ashift value should correspond with your drives' physical sector size. An ashift of 9 corresponds to 512 byte sectors and an ashift of 12 corresponds to 4KiB sectors (\(2^9 = 512\), \(2^{12} = 4096\)). 99.9% of the time, ZFS will correctly detect the sector size of your drives and set ashift automatically but it's always good to double-check. Run the following command in the shell as root if you've already created your pool: zdb -U /data/zfs/zpool.cache | grep ashift
If you're running drives with 4KiB sectors, this should say "ashift: 12" at least one time, maybe more (it prints it once per vdev for all pools). If you have any "ashift: 9", you can remove the | grep ashift part of the command and rerun it to see which pool it corresponds to. If your boot pool has a mismatched ashift value, you can safely ignore it as the boot pool isn't used for any performance-sensitive operations.
If your pool does have the wrong ashift value, it may not necessarily be the end of the world. If you have drives with 512 byte sectors and your ashift is 12, this just means the system is going to be working on a minimum of 4 sectors at a time. Modern applications rarely work with less than 4KiB at a time anyway, so (as we'll discuss in the recordsize section below) you probably won't see a large performance hit by running ashift=12 vs =9.
If, however, your ashift is smaller than what it should be (4KiB sector drives with ashift 9), your pool will likely be performing significantly worse than it could be. The smallest unit of storage your drive can support is 4KiB, but ZFS thinks it can work with 512 bytes at a time. When ZFS asks your drive to write 512 bytes of data, the drive needs to read the target 4KiB sector, modify its contents to include your 512 byte update, and rewrite the whole thing back to disk. This is a process called write amplification or a read-write-modify cycle and will cause a system dealing with lots of small I/O's to run much slower than it should. Reads are slower too because the drive needs to pull 4KiB of data from the disk only to return 512 bytes of it and discard the rest.
If you do need to change the ashift value on an existing pool, you'll unfortunately need to destroy and recreate that pool. (While this may seem obvious, it's probably worth mentioning: back up all your data before destroying your pool!) To override the TrueNAS UI's auto-ashift on pool creation, you'll need to use the shell command zpool create. Make sure to add the -o ashift=12 flag to the command (obviously, change the "12" to whatever your ashift should be). The documentation for zpool create can be found here.
Some disks (particularly NVMe SSDs) let you change the sector size between 512 bytes and 4KiB. 4KiB sectors will almost always perform better on a drive that supports both, but check with your drive manufacturer's documentation to confirm. Sometimes, SSDs support 8KiB or even 16KiB sectors. If the manufacturer claims these run faster, use those sector sizes! You would set ashift=13 and ashift=14 respectively. Changing the sector size of the physical disk might be a simple one-line command or it might require a firmware reflash. Either way, do this before you create your pool.
Dataset recordsize and volblocksize
Once you have confirmed that your pool's ashift is properly set, you can turn to dialing in the recordsize and volblocksize values. The recordsize property is only applicable to file system datasets and the volblocksize property is only applicable to volume datasets (zvols). Note that changing the recordsize will only affect newly-written data (volblocksize can not be changed after zvol creation). Existing data must be rewritten to see the effect of the new recordsize.
On file system datasets, ZFS will dynamically size its blocks based on how much data it has to write out. The blocks will have a minimum size of 2^ashift (which is ideally your drives' sector size) and a per-dataset property called the "recordsize". The recordsize can be set in powers of 2 between 2^ashift and 1024KiB (so for ashift=12, valid recordsize values would be 4K, 8K, 16K, 32K, 64K, 128K, 256K, 512K, and 1024K/1M). OpenZFS also has support for recordsize values of 2M, 4M, 8M, and 16M, but these should be considered experimental and can only be accessed by changing the zfs_max_recordsize kernel module parameter.
The recordsize value should be set to match the expected workload on that dataset, specifically the typical size of the I/O on that dataset. If you set the recordsize too high and write out lots of tiny files, ZFS will aggregate all those files in a single large block. If you ever read back one of those tiny files, ZFS will need to read the whole large block which will increase latency and reduce read throughput. On the other hand, if you set the recordsize too low, large files will get split between lots of tiny blocks which will increase storage overhead and I/O latency.
A workload that exclusively uses a single I/O size is the easiest to tune for. A good example of this is BitTorrent which performs all operations at 16KiB reads and writes. This means if you have a dataset hosting storage for a BitTorrent client, you should set the recordsize for that dataset to 16KiB to maximize performance. If the files you're downloading are all multiple gigabytes in size, you might move them to another dataset with 1MiB recordsize after they're finished to increase storage efficiency. This also has the added benefit of defragmenting the blocks for that file. BitTorrent writes data in a very random manner so blocks for a single file could otherwise end up scattered all over the disks.
A dataset hosting database files will perform best if the recordsize on that dataset is set to the database's page size (assuming the database does 1 page per I/O). PostgreSQL has a page size of 8KiB, so a dataset hosting PostgreSQL data should have its recordsize set to 8KiB. InnoDB uses a page size of 16KiB, so recordsize values should match that. SQL Server has a page size of 8KiB but it does its I/O in units called "extents" which are 8 pages each, so recordsize values for SQL Server should be set to 64KiB.
If your datasets are supporting a more mixed workload like a home media server, think through the smallest files you're likely to be storing. If you have lots and lots of MS Office docs and PDFs that are tens of kilobytes each and that you access pretty regularly, the default 128KiB recordsize is likely best. If most of your files are movies and photos and music that are all larger than 1MiB each, then 1MiB recordsize is probably better.
A zvol has a very similar parameter to recordsize called the volblocksize. Unlike file system datasets, however, zvols do not use variable block sizes. All blocks written to a zvol will be sized at the volblocksize. The same logic for tuning the recordsize to a workload applies to tuning the volblocksize. On TrueNAS, valid volblocksize are 4K, 8K, 16K, 32K, 64K, and 128K. OpenZFS recently added support for volblocksize values all the way up to 16M but these have not been well tested so they have not been added to the TrueNAS UI yet. If you want to experiment with large volblocksize values, you'll need to create your zvol through the CLI. If you want to go over volblocksize=1m, you'll need to change the zfs_max_recordsize kernel module parameter.
If you're using RAIDZ, changing the recordsize can also change your overall storage efficiency (beyond just fitting files into appropriately-sized blocks). Because of the way ZFS lays blocks out across RAIDZ stripes, it sometimes has to add extra parity and padding sectors to the block. The amount of extra parity and padding depends on the stripe width and the block size. Obviously, the stripe size is fixed but the block size can vary based on setting the recordsize and volblocksize values. If you want to get a better idea of how your storage efficiency might change based on different block sizes, check out the calculator here.
Changing the "ZFS recordsize value" on the calculator linked above will change the projected usable capacity displayed in the tables below. A more detailed explanation of this phenomenon can be found on the walkthrough section of that page as well as on this page.
Dataset atime
The access timestamp (or atime) keeps track of the last time a file was accessed (read from or written to). While this can be a useful statistic to track and may even be vital for certain applications, it does add some file system overhead. If your workload does not need to track file access times, you can disable atime tracking per dataset. Don't expect a night-and-day performance difference but every little bit helps.
If you change this setting on a pool with existing data, ZFS doesn't go and delete all the access timestamps for existing files, it just stops tracking it going forward. In other words, you don't really need to rewrite any data to see the effect of an atime setting change.
Sync Settings
The SLOG and ZIL section of this guide walk through the sync write process in ZFS in extensive detail. As mentioned in that section, ZFS provides a way to override an application sync setting. This can be useful in two cases: if you have an application that is doing sync writes and you don't want it to, or you have an application NOT doing sync writes and you DO want it to.
An example of the former might be BitTorrent storage. Sync writes are slower than async writes but provide better data integrity. With BitTorrent, if you lose the last ~5 seconds of downloads, you can just check the torrent and redownload whatever was lost. With that in mind, you might set your torrent download dataset to sync=disabled (assuming it's running over a protocol doing sync writes in the first place like iSCSI or NFS).
On the other hand, a database that loses the last 5 seconds of write data might mean thousands of dollars lost to a big important company. If that is the case for your iSCSI- or SMB-based database storage, set sync=always on their datasets. Note that if you run sync=always, you will want a fast SLOG on the pool.
Extended Attributes
From the Linux man pages, extended attributes (or "xattrs" for short) are "often used to provide additional functionality to a filesystem: for example, additional security features such as Access Control Lists (ACLs) may be implemented using extended attributes." ZFS provides support for two different styles of extended attributes: directory-based and system-attributes-based (it also lets users disable xattrs entirely for a given dataset). It's not critical to fully understand the difference between these two styles of xattrs, suffice to say directory-based xattrs are more broadly compatible but slower than system-attribute-based xattrs. Directory-based xattrs make lots of tiny hidden files to track the attributes which can cause extra I/O while system-attribute-based xattrs embed the attributes into the relevant files and folders.
Which style of extended attributes ZFS uses on a given dataset is controlled via a property called "xattr". Valid options are "on", "off", and "sa". The default value is "on" which uses the slower (but more widely-compatible) directory-based xattrs. It should be perfectly safe for TrueNAS CORE and SCALE users to set "xattr=sa" on all file system datasets for a potential performance boost. You can also disable xattrs entirely on a dataset by setting "xattr=off".
This needs to be set through the CLI (as root) using: zfs set xattr=sa $dataset
Dnode Size
Dnodes are fundamental objects created by ZFS' Data Management Unit (DMU) to track user files and folders as well as lots of other internal ZFS stuff. ZFS provides the ability to set the expected dnode size per dataset using the appropriately-named "dnodesize" property. By default, this is set to "legacy" which (like the xattr setting above) is more in the spirit of broad compatibility than performance. If you're running a file server on your TrueNAS and have set "xattr=sa" as above, ZFS' dnodes can potentially grow beyond what the "legacy" setting can gracefully handle. Instead, you can use "dnodesize=auto" to let the dnode size grow to accommodate the embedded xattrs.
You can explicitly set the dnodesize property to 1k, 2k, 4k, 8k, or 16k if you know the optimal dnode size in advance.
To set the dnodesize property to "auto" in TrueNAS, run the following command in the shell as root: zfs set dnodesize=auto $dataset
Log Bias
Datasets in ZFS can have a property set called "logbias" which (according to the OpenZFS man pages) "provide[s] a hint to ZFS about handling of synchronous requests in this dataset". Valid options for this parameter are "throughput" and "latency" with the latter being the default. If the logbias property is set to "throughput", ZFS will not use configured log devices on that dataset and instead "optimize synchronous operations for global pool throughput and efficient use of resources."
In other words, if you have a SLOG configured, you probably don't want to set logbias=throughput. The only situation where you have a SLOG and might set this is if you have some datasets that are latency sensitive and others that are not latency sensitive but all datasets are sync-write heavy. By setting logbias=throughput on the non-latency-sensitive datasets, it's possible to preserve SLOG utilization for the other datasets. This is probably not a very common scenario.
If you're running an all flash pool and are not using a SLOG device, you might see increased write throughput by setting logbias=throughput. It will likely be workload dependent so do plenty of testing, but it's worth trying.
Note the logbias setting is not exposed in the TrueNAS UI and will need to be set via CLI (as root) using: zfs set logbias=throughput $dataset
Snapshot Directory
This isn't a performance tune so much as it is a quality-of-life tune. File system datasets have a property called "snapdir" that is by default set to "hidden". If changed to "visible", there will be a hidden .zfs directory at the root of the dataset that contains a folder with all the available snapshots for that dataset. This means if you accidentally delete a file, you can easily browse to /dataset/.zfs/snapshots/$snapshot_name/ and recover the file. Snapshots are read-only so you won't be able to modify or delete any of these files unless you mount the snapshot as a clone. The TrueNAS UI exposes this option on all file system datasets. If you leave the snapdir property set to "hidden", you can still access the .zfs folder from the shell (i.e., to cp files from a snapshot to the live filesystem) but you won't be able to access it through the Windows file explorer on mounted shares.
Primary and Secondary Cache Settings
ZFS lets you define how individual datasets and zvols should use both the primary and secondary caches (the ARC and L2ARC). This is provided via the "primarycache" and "secondarycache" dataset options. Valid settings are "all", "metadata", and "none". The "all" option is default for both and will let the dataset take full advantage of the respective cache, the "none" option will disable the use of the primary or secondary cache for that dataset, and the "metadata" option will limit cache usage to metadata.
You might use this on systems supporting mixed workloads if you want one workload to leave the L2ARC alone. In that case, you would set "secondarycache=none" on the datasets that shouldn't touch L2ARC.
Users with very large datasets and a relatively small L2ARC might benefit from setting "secondarycache=metadata". This will help accelerate access to a wide range of files without taking up tons of space with actual file contents. Users with large video production environments have (anecdotally) reported success with setting "secondarycache=metadata" on active media storage datasets; if you host a similar environment, it may be worth trying out.
The primarycache and secondary cache settings are not exposed in the TrueNAS UI. To change them, use the same zfs set syntax covered above.
Dirty Data Deep-Dive
OpenZFS offers several methods to tune how it handles in-flight or "dirty" data. As a reminder, dirty data is data that has been written to a ZFS system but only exists in RAM. ZFS flushes dirty data from RAM out to the pool on a regular basis but it lets you control exactly how often it does this flush. The methods for controlling how OpenZFS handles its dirty data are very incredibly confusing and poorly documented, so it's worth attempting to demystify them here.
As discussed in the ZIL, SLOG, and Sync Writes section above, dirty data is aggregated in memory in a data structure called a transaction group or "txg". The data in the transaction group gets flushed to disk either when a pre-set timeout interval occurs or when the transaction group reaches a certain size, whichever happens first. The timeout interval defaults to five seconds and is controlled by the zfs_txg_timeout module parameter. The txg size threshold is controlled by the zfs_dirty_data_sync_percent module parameter. This defaults to 20% of the value of the zfs_dirty_data_max parameter.
If you look at the zfs_dirty_data_max parameter, you may notice that there are actually four different ways to set a cap on how much dirty data ZFS can handle: zfs_dirty_data_max, zfs_dirty_data_max_max, zfs_dirty_data_max_percent, and zfs_dirty_data_max_max_percent. The module parameters ending in _percent are an alternative method to setting these limits as a percent of total system memory. If you set both the explicit value parameter and the percent parameter, the explicit value parameter will take precedence.
The zfs_dirty_data_max parameter defaults to whichever is smaller: 10% of physical RAM or zfs_dirty_data_max_max. The zfs_dirty_data_max_max parameter defaults to whichever is smaller: 4GiB or 25% of physical RAM. Why the developers chose to implement the dirty data limits like this is anyone's guess... To simplify: if you have 40GiB of RAM or less in your system, zfs_dirty_data_max will be 10% of installed memory. If you have more than 40GiB of RAM, zfs_dirty_data_max will be 4GiB. Once you know your maximum dirty data size, 20% of that is the zfs_dirty_data_sync_percent value (819.2 MiB if your zfs_dirty_data_max is 4GiB).
OpenZFS also includes a transaction delay mechanism to gently put the brakes on incoming writes if they're drastically outpacing the underlying pool drives. You can read more about that here. The point at which the brakes start to get applied (referred to as "write throttling") is controlled by the zfs_delay_min_dirty_percent parameter and defaults to 60%. This is also a percent of the zfs_dirty_data_max value. With the default settings of 20% for zfs_dirty_data_sync_percent and 60% for zfs_delay_min_dirty_percent, this implies that ZFS will let about three full transaction groups pile up before it throttles incoming write operations by adding artificial latency. Initially, ZFS will add very small delays in each operation, just a few microseconds. If the dirty data still continues to pile up despite these added delays, ZFS will add exponentially more delay to each write operation until eventually it's adding an enormous 0.1 seconds and effectively slamming on the brakes until the pool disks can catch up. You can also tune the general shape of the throttling curve by changing the zfs_delay_scale parameter.
If you have a large amount of RAM in your system, it should be safe to bump up zfs_dirty_data_max and zfs_dirty_data_max_max to 10% of installed memory. Note that while you can set zfs_dirty_data_max dynamically, changing zfs_dirty_data_max_max requires a reboot to come into effect. You can (amusingly enough) set zfs_dirty_data_max to a value larger than your zfs_dirty_data_max_max but it will revert on reboot. Unless you really know what you're doing, it is not recommended that you change the zfs_dirty_data_sync_percent, zfs_delay_min_dirty_percent, or zfs_delay_scale parameters.
Sizing RAIDZ vdevs to minimize overhead
Ideal RAIDZ vdev width is a very common point of discussion (and misunderstanding) in ZFS communities. The so-called \(2^n + p\) rule has been passed around and almost treated as gospel for so long it's difficult to track down its origin. Proponents of the rule often claim (in a very hand-wavy way) that sizing a RAIDZ vdev such that the quantity of data disks in that vdev is an even power of two will optimize storage efficiency and performance. The rule gets its name from \(2^n\) being the even power of two and \(p\) being the added parity disks from RAIDZ1, Z2, or Z3. For example, if you want to use RAIDZ2, you would do well to make sure you have 2, 4, or 8 data disks making your total vdev width 4, 6, or 10. If you deviate from this rule, you may (or may not) suffer eternal torment in ZFS hell for vague but extremely consequential reasons. Like so many of the rules-of-thumb in the IT world, the 2^n + p rule gets it a bit less than half-right.
When a block is written to a RAIDZ vdev (be it Z1, Z2, or Z3), that block gets split out between all the disks that compose that vdev. ZFS sometimes has to add some extra data to the block so it's optimally spread across all the disks. This is referred to as "allocation overhead". The data that ZFS adds to the block is either extra parity information, extra padding, or sometimes both. Having any allocation overhead will reduce overall storage efficiency of the vdev and thus the pool.
Extra parity sectors are added to each block if the total size of the block doesn't evenly divide among all the disks. For example, we have the 10wZ2 layout below. The "P" cells in the table represent parity sectors on each disk and the "D" cells represent data sectors on each disk. The block we're writing is 128KiB and we're assuming the on-disk sectors are 4KiB each. This gives us 32 total data sectors to write and eight parity sectors to write:
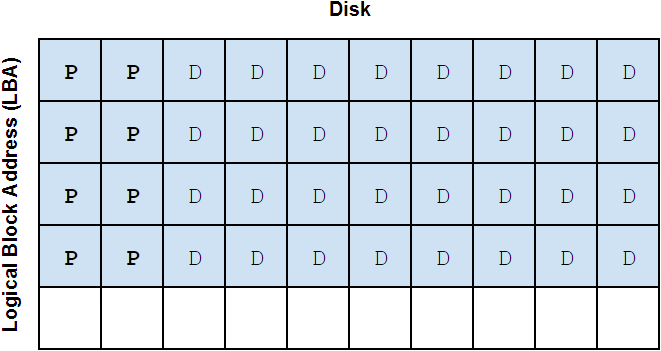
On the 9wZ2 layout below, we can see that the 32 data and eight parity sectors can't evenly be divided between the nine disks, so we need a couple of extra parity sectors to cover the overflow data. This is what reduces the overall storage efficiency of this RAIDZ2 layout:
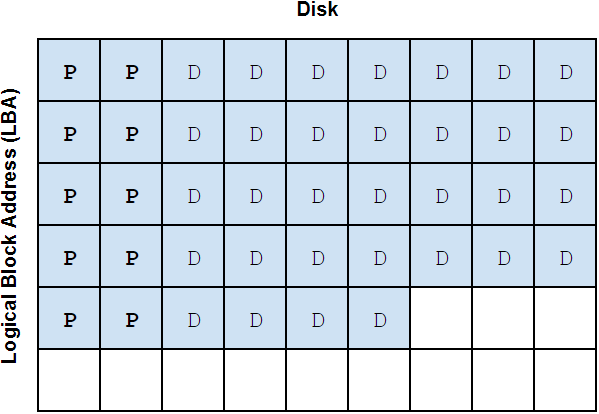
These extra parity sectors get added when a "partial stripe write" happens. "Partial stripe write" is the technical term for the overflow data we saw in the 9wZ2 example. Partial stripe writes occur when ZFS writes a block to a RAIDZ vdev where the quantity of data disks is not an even power of two. In other words, this is the inefficiency that the users adhering to the \(2^n + p\) rule would avoid. This does assume that a) the size of the block being written is also an even power of two, and b) the block is large enough to fill the full stripe width. For users working with large files, this will almost always be the case.
The second source of additional data being added to a block (and the overhead that isn't addressed by the \(2^n + p\) rule) is padding. ZFS adds padding to RAIDZ blocks if the total number of sectors written out (including parity and data) is not an even multiple of \(1 + p\) where \(p\) is the parity depth (1 for Z1, 2 for Z2, 3 for Z3). ZFS ensures blocks are always sized to be an even multiple of \(1 + p\) because this is the smallest usable on-pool space (1 data sector and \(p\) parity sectors). If ZFS let any old block with an oddball size onto the pool, it would likely end up unusably small gaps on the disks after deleting and re-writing some data. A lot more background on this can be found in the guide section of the capacity calculator tool here.
We can revisit our 10wZ2 and 9wZ2 examples above and add padding to ensure the total quantity of sectors written is an even multiple of \(1 + p\) (which equals three in this case because we're using RAIDZ2). Note that "X" cells are padding sectors.
The 10wZ2 layout is below:
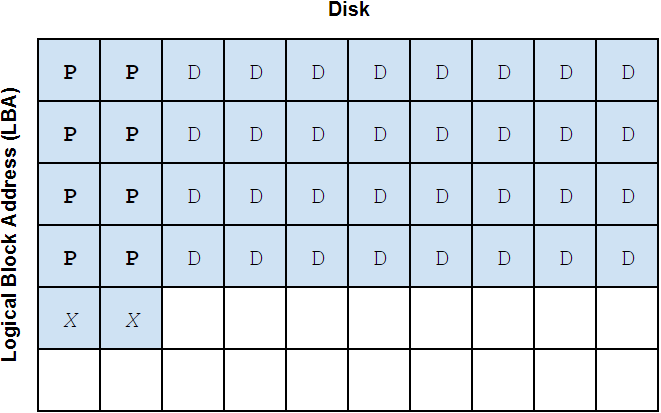
With 32 data sectors and eight parity sectors, the block initially had 40 total sectors. 40 is not an even multiple of three, so ZFS adds two padding sectors to bring the total sector count to 42 (which, notably, is an even multiple of three). We can see that even though the 10wZ2 vdev adheres to the \(2^n + p\) rule, it's not immune from RAIDZ allocation overhead.
The 9wZ2 example is below:
Lo and behold, the 9wZ2 example already added two additional sectors to the block in the form of partial-stripe parity, so the total sector count was already at 42 and no additional padding is needed. The 9wZ2 layout, despite not complying with the \(2^n + p\) rule, has the same exact amount of RAIDZ allocation overhead as the 10wZ2 layout.
Determining whether a given RAIDZ vdev of arbitrary width will have a lot of allocation overhead from padding is a bit more complex. As we just covered, if the total number of sectors to be written to the vdev is not an even multiple of \(1 + p\), ZFS will add padding. The question that naturally follows is "how do we figure out the total number of sectors to be written?"
The first step in that calculation is to determine the total number of data sectors (as opposed to parity sectors) we'll need. In the OpenZFS Tuning section below, we'll discuss how ZFS dynamically sizes blocks to best fit the data being written. The maximum block size is enforced by a per-dataset value called the recordsize. A dataset's recordsize value could be any power of two between the sector size and 1MiB (so assuming 4KiB sectors, the recordsize could be 4KiB, 8KiB, 16KiB, 32KiB, 64KiB, 128KiB, 256KiB, 512KiB, or 1024KiB). Blocks written to a dataset could be smaller than the recordsize value and could even be in-between sizes (i.e., if you have recordsize=128KiB, you could have some blocks on the dataset that are 112KiB wide). It's far more common for the vast majority of blocks on the dataset to be the same size as the dataset's recordsize value, so we'll use that assumption for our calculations here. If we assume the block to be written is equal to the recordsize, the number of data blocks to be written to the vdev will be:
$$ \frac{recordsize}{\text{sector size}} $$
Once we have the number of data blocks determined, we need to calculate the number of parity blocks we'll need. We know we'll need p parity blocks per stripe. To determine the number of stripes, we can divide the number of data blocks (calculated just above) by the number of data blocks we can have per stripe. The number of data blocks per stripe is equal to the vdev width minus p (the number of parity sectors per stripe).
$$ \frac{recordsize / \text{sector size}}{\text{vdev width} - p} $$
As we saw in the 9wZ2 example, we can have partial stripes, meaning the equation above might not give us an integer. Since we're using this to determine the number of parity sectors we need on the block and even fractional stripes get a full set of parity sectors, we'll round this result up to the nearest whole number using the ceiling function. We can then multiply that by \(p\) to get the total number of parity sectors on the block:
$$ p * ceiling\left(\frac{recordsize / \text{sector size}}{\text{vdev width} - p}\right) $$
We can add this result to the formula above for number of data sectors to get the total number of sectors in the block:
$$ p * ceiling\left(\frac{recordsize / \text{sector size}}{\text{vdev width} - p}\right) + \frac{recordsize}{\text{sector size}} $$
If the result of this is an even multiple of \(1 + p\), then ZFS will not need to add any padding. If it's not an even multiple, ZFS will need to add up to p padding sectors to the block so it becomes an even multiple of \(1 + p\). The "\(p * ceiling( (recordsize / \text{sector size}) / (\text{vdev width} - p) ) + (recordsize / \text{sector size})\) rule" doesn't exactly roll off the tongue, so we'll refer to this as the \(1 + p\) rule instead.
Somewhat interestingly, a given RAIDZ vdev width may experience padding with some recordsize values and not with others. As we covered above, using a 128KiB recordsize results in 42 sectors in the block and no additional padding. However, if we re-run the numbers on the 9wZ2 vdev using a 512KiB recordsize, we will find that we end up with 166 total sectors in the block. 166 is not an even multiple of three and thus needs two padding sectors. With recordsize=1024KiB, we have 330 total sectors which is an even multiple of three. Other vdev widths (covered below) will consistently avoid block padding regardless of the dataset's recordsize value.
To summarize what we've covered above, a more accurate rule-of-thumb for users that want to totally eliminate allocation overhead is a combination of the \(2^n + p\) and \(1 + p\) rules. For RAIDZ2, the only practically-sized vdev width that totally eliminates allocation overhead is six:
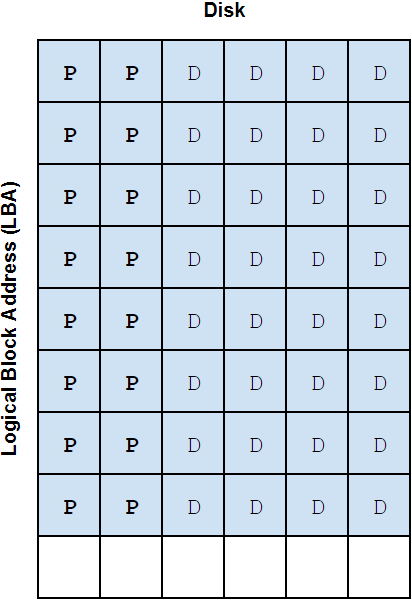
A 6wZ2 vdev has 4 data disks, which is an even power of two, and if we run through the math we covered above, will always end up with a block size that's a nice even multiple of 3, thus we do not need any partial-stripe parity or padding sectors. The next RAIDZ2 vdev with that meets both of these requirements is 18, but as covered above, that's far too wide to be practical. For RAIDZ1, widths that avoid any allocation overhead are 3w, 5w, 9w, and 17w. For RAIDZ3, 7w, 11w, and 19w all avoid allocation overhead.
Despite having more allocation overhead, oddly-sized RAIDZ vdevs that are larger will pretty much always have more usable capacity than the ideally-sized 6wZ2 vdev. If you have 60 total drives, 6x 10wZ2 vdevs will net you much more usable capacity than 10x 6wZ2 vdevs. If you have 42 total drives, 6x 7wZ2 vdevs (a vdev width that has partial stripe parity and padding sectors) will usually net you a bit more capacity than 7x 6wZ2 vdevs ("usually" because with some drive sizes, 7x 6wZ2 will net a couple dozen more GiB than 6x 7wZ2). If you're working predominantly with large files, you can dramatically reduce how much allocation overhead you experience (even on oddball vdev widths) by increasing the recordsize value on your datasets. You can read more about this in the OpenZFS Tuning section below. You can also play with the calculator on this page: try setting the "Table Data" selector to "ZFS Overhead" and look at the overhead percentages for different vdev widths. Then try changing the recordsize value to see how it impacts the allocation overhead. Larger recordsize values will reduce overhead. This is because the additional parity and padding sectors get added per block; the impact of those extra few sectors is much more significant if the blocks are only 42 sectors wide compared to blocks which are several hundred sectors wide.
ZFS guides that mention the \(2^n + p\) rule also commonly claim that designing your RAIDZ vdevs in this way will increase (or at least optimize) performance. While reading a couple extra sectors from a disk will take a bit more time, the decrease in performance is completely negligible. Those extra sectors will be directly adjacent to the sectors ZFS would already otherwise be reading so the disk will not experience any additional seek or rotational latency. Without any added latency, these 4KiB sectors can be pulled from the disk at its full sequential read speed (which can be 250MiB/s on higher-density 7200RPM drives). This means the extra 4 KiB sector would take on the order of an extra 15 to 20 microseconds to pull from each disk. In the case of partial-stripe parity sectors, the extra reads really add no additional time to the overall I/O because other disks in the vdev are reading another sector anyway and the call wouldn't return any data until they complete. In short: if RAIDZ allocation overhead reduces performance at all, the reduction is so small it can be completely ignored.
This whole section was a long-winded (and, admittedly, somewhat ranty) way of saying "don't worry too much about optimizing vdev width". If you need usable capacity more than you need performance, go with wide vdevs (but not too wide). If you need more performance, go with a larger quantity of more narrow 6-wide RAIDZ2 vdevs or go all the way and just run mirror vdevs. If you only have 12 drive bays to work with, 2x 5wZ2 vdevs might be a better choice than 2x 6wZ2 vdevs so you can fit a hot spare and maybe a SLOG or L2ARC drive in the system too. Finally, make sure to adjust the recordsize of your datasets to match the workload they're supporting, then just let OpenZFS worry about the rest.
dRAID Internals
The layouts displayed with the examples in the above dRAID section were not shuffled and thus do not represent what is written to the pool. When shuffling the on-pool data, ZFS uses hard-coded permutation maps to make sure a given configuration is shuffled the exact same way every time. If the permutation maps were ever allowed to change, un-shuffling terabytes of data would be an enormous task. The OpenZFS developers created a different permutation map for every value of c in a dRAID vdev (more specifically, they selected a unique seed for a random number generator which in turn feeds a shuffle algorithm that generates the maps).
Each row of the permutation map is applied to what dRAID calls a slice. A slice is made up of the minimum set of full rows we need to hold a full set of redundancy groups without any part of the last group spilling over into the next row. This is somewhat difficult to grasp without being able to visualize it, so the draid2:6d:24c:1s example from above is shown below with its slices noted:
Notice how 23 redundancy groups take up exactly 8 rows. If we work with any fewer than 8 rows, we'll have at least one partial redundancy group. The number of redundancy groups in a slice can be determined by:
$$ \frac{LCM(p+d,c-s)}{(p+d)} $$
The number of rows in a slice can be determined by:
$$ \frac{LCM(p+d,c-s)}{(c-s)} $$
If the redundancy groups line up nicely (as they did in the draid2:6d:24c:0s example), then a slice will only contain a single row:
As we noted above, the permutation maps get applied per-slice rather than per-row. After shuffling, the draid6:2d:24c:1s vdev will be laid out as below:

Notice how within a slice, the rows in a given column all match; this is because all the rows in a slice get the same permutation applied to them.
Once shuffled, the draid6:2d:24c:0s vdev will be laid out as below:
As expected, each row gets a different permutation because our slice only consists of a single row.
When studying the above diagrams, you may intuitively assume that each box represents a 4KiB disk sector, but that is not actually the case. Each box always represents 16 MiB of total physical disk space. As the developers point out in their comments, 16 MiB is the minimum allowable size because it must be possible to store a full 16 MiB block in a redundancy group when there is only a single data column. This does not change dRAID's minimum allocation size mentioned above, it just means that the minimum allocation will only fill a small portion of one of the boxes on the diagram. When ZFS allocates space from a dRAID vdev, it fills each redundancy group before moving on to the next.
The OpenZFS developers carefully selected the set of random number generator (RNG) seeds used to create the permutation mappings in order to provide an even shuffle and minimize a given vdev's imbalance ratio. From the vdev_draid.c comments, the imbalance ratio is "the ratio of the amounts of I/O that will be sent to the least and most busy disks when resilvering." An imbalance ratio of 2.0 would indicate that the most busy disk is twice as busy as the least busy disk. A ratio of 1.0 would mean all the disks are equally busy. The developers calculated and noted the average imbalance ratio for all single and double disk failure scenarios for every possible dRAID vdev size. Note that the average imbalance ratio is purely a function of the number of children in the dRAID vdev and does not factor in parity count, data disk count, or spare count. The average imbalance ratio for a 24-disk dRAID vdev was calculated at 1.168.
The developer comments note that...
...[i]n order to achieve a low imbalance ratio the number of permutations in the mapping must be significantly larger than the number of children. For dRAID the number of permutations has been limited to 512 to minimize the map size. This does result in a gradually increasing imbalance ratio as seen in the table below. Increasing the number of permutations for larger child counts would reduce the imbalance ratio. However, in practice when there are a large number of children each child is responsible for fewer total IOs so it's less of a concern.
dRAID vdevs with 31 and fewer children will have permutation maps with 256 rows. dRAID vdevs with 32 to 255 children will have permutation maps with 512 rows. Once all the rows of the permutation maps have been applied (i.e., we've shuffled either 256 or 512 slices, depending on the vdev size), we loop back to the top of the map and start shuffling again.
The average imbalance ratio of a 255-wide dRAID vdev is 3.088. Somewhat interestingly, the average imbalance ratio of the slightly-smaller 254-wide dRAID vdev is 3.843. The average imbalance ratios show an unusual pattern where the ratio for vdevs with an even number of children is typically higher than those with an odd number of children.
The algorithm used to generate the permutation maps is the Fisher-Yates shuffle, the de facto standard of shuffle algorithms. The RNG algorithm used, called xoroshiro128++, is based on xorshift. In the dRAID code, this algorithm is seeded with two values to start the permutation map generation process: one seed that's specific to the number of children in the vdev, and one hard-coded universal seed which, amusingly enough, is specified as 0xd7a1d533d ("dRAIDseed" in leet-speak when represented in hex).
dRAID Visualized
Below is an interactive dRAID vdev visualizer. You can specify any valid dRAID layout and see it both in a pre-shuffled and a post-shuffled state. It uses the same RNG algorithm and seeds as the ZFS code, so it should accurately represent how everything gets distributed in a dRAID vdev. The average imbalance ratio of the vdev and the physical on-disk size of each box is displayed at the bottom.
|
draid
:
d
:
c
:
s
Enter dRAID vdev parameters above
|
1
Disk
1
Parity
1
Data
1
Spare
0
Slice
|
|
|
|
ZFS Module Parameters
There are many, many ZFS module parameters that can drastically change the way your system behaves. Full documentation on all of these can be found here.
As mentioned above, changing these can potentially break your system so proceed with caution. To add these to TrueNAS, go to System > Tunables and add them as a sysctl tunable prefixing each with "vfs.zfs." (so l2arc_noprefetch becomes vfs.zfs.l2arc_noprefetch). Any parameter dealing with data sizes will want bytes as an input, so set 1048576 to input 1MiB.
l2arc_noprefetch: By default, prefetched data will skip over the L2ARC. If you have a workload that uses a lot of prefetch and you have a lot of L2ARC, you can set this tunable to "0" so prefetched data WILL go into L2ARC.
l2arc_write_max: This sets a (soft) limit on how fast data can be written to each L2ARC device. The default is 8MiB/s (8388608). If your L2ARC device is fast, you can bump this by a factor of 10x (83886080). Don't set it too high or read speed will be impacted. If you don't have an L2ARC, you can skip this.
l2arc_write_boost: When the ARC hasn't filled up yet, ZFS will increase the write_max limit above by this amount. The default is 8MiB. This can also be increased by 10-20x if your L2ARC device(s) are fast enough.
zfs_arc_max:This limits the size of the main ARC. On Linux systems, it defaults to half of the total system memory and on FreeBSD it's 5/8ths of system memory. The defaults are set conservatively because it's common to run OpenZFS on systems with lots of other applications. On a dedicated NAS that isn't hosting any VMs or containerized apps, it's possible to push this limit up quite a bit. If you aren't using plugins or jails, it should be safe for TrueNAS CORE users to set this to 90% of your total system memory. Note that there is a bug on OpenZFS's Linux version that prevents ARC from exceeding 50% of total memory regardless of this setting so SCALE users might not benefit from changing this.
zfetch_max_distance: This limits the number of bytes ZFS will prefetch per read stream. The default is 8MiB. If you're using large blocks (recordsize=1MiB), you can bump this up to 64MiB (67108864).
metaslab_lba_weighting_enabled: On modern hard drives, tracks towards the outside of each magnetic platter can have significantly greater bandwidth than tracks towards the inside of the platter. ZFS takes advantage of this by preferring to write data in the outer zones of hard drives. On SSDs, you should get even performance across the whole disk, so this behavior doesn't make sense and can be disabled by setting this to 0. OpenZFS v0.6.5 and later will check and set this automatically but if you have an old version of OpenZFS or you're using SSDs that misrepresent themselves to the OS as rotational media, set this to 0. This is set system-wide, so only change it if you're running all SSDs that misrepresent themselves.
zfs_max_recordsize: As mentioned in the recordsize section, this controls the maximum recordsize and volblocksize value you're allowed to apply to file system and volume datasets. By default, it's set to 1M (1048576) but can be set all the way up to 16M (16777216). Setting a recordsize value above 1M or a volblocksize value above 128k should be considered experimental.
The Final Word in File Systems
When its creators presented ZFS at the Storage Networking Industry Association (SNIA) Storage Developers Conference (SDC) in 2008, they referred to it as "The Last Word in File Systems".
This slide deck was presented roughly seven months before Oracle Corporation announced it would acquire Sun for US$7.4 billion. Shortly after the deal was completed in early 2010, Oracle took the ZFS project closed-source.
Owing largely to its open-source licensing, OpenZFS is far more popular today than the proprietary Oracle ZFS. A strong argument could be made that this open-source version deserves the mantle of "The Last Word in File Systems" more than Oracle's version. (Personally, I think "The Final Word in File Systems" sounds better because of the alliteration, hence the title of this article).
What did the researchers at Sun Microsystems mean when they called ZFS "The Last Word in File Systems"? Their software certainly improved (or even revolutionized) many aspects of storage management such that administrators may never want to host their data on another platform again. Its developers also built ZFS such that administrators would not run into arbitrary limits on their system as storage technology improved.
Many file systems from even recent history are built such that they have scalability limits on things like the maximum volume size, the maximum size of a single file in a volume, or the maximum number of files it can handle in a single directory. Ext3, for example, was originally released in 2001 and was not replaced until 2008 and limited the maximum volume size to 32 TiB. Ext4, the default file system in many Linux distributions including Debian and Ubuntu, increased this limit to 1 EiB (or 1024 PiB), but it's not inconceivable that storage administrators will be bumping into this or another hard limit before too long.
Usually, these limits are related to the number of bits the file system uses to track and manage data. 32-bit file systems have all but been replaced by 64-bit file systems today, but hard drive sizes and data storage demands continue to grow at an exponential rate and it won't be long before admins need to migrate data to a more modern file system yet again. The developers of ZFS aimed to totally do away with these relatively small, incremental improvements by implementing a 128-bit file system that can handle such an absurdly large amount of storage, there is no conceivable way the human race would run into any of its limits in the next thousand years.
The maximum capacity of a ZFS pool is \(2^{128}\) bits. This amount of storage is so far outside our comprehension, it's worth exploring it a bit more to fully appreciate just how huge it is.
The largest CMR hard drive available at the time of writing is 22TB. It occupies a physical space of about 391 cubic centimeters. If we somehow produced and gathered enough of these hard drives to completely max out a ZFS pool, those drives would be 70% the size of the earth. This doesn't account for any of the chassis to house the drives, the cabling, or the server system managing everything.
According to the spec sheet, idle power draw for each of these drives is 6 watts, so our full set of \(1.933 * 10^{24}\) drives would consume \(1.16 * 10^{25}\) watts at idle (and only a modest increase to 1.93 * 10^25 watts while active). The sun produces \(3.8 * 10^{26}\) watts, meaning we would need something like a Dyson sphere to even power a system hosting this many disks.
We can take things even further: a single ZFS system can support up to \(2^{64}\) pools. A set of 22TB drives to fully max out every pool on a single ZFS system would occupy a volume more than 16 times larger than our solar system. The Milky Way has between 100 and 400 billion stars in it and if we had a Dyson sphere around every single one operating at 100% efficiency with no transport loss, we would not even come close to having enough power to spin up all our drives.
Of course, hard drive capacities are continuing to increase and maybe in 1,000 years time we will have drives so dense and so efficient that the above math works out to something a bit more reasonable. We can take drive capacity to the extreme and imagine a storage device where the bit density is the same as the density of hydrogen atoms in the sun. With this density, a standard 3.5" hard drive would hold about 34,903 zettabytes of data (1 zettabyte is 1,000 exabytes and 1 exabyte is 1,000 petabytes). If we had enough of these miraculous drives to max out a single ZFS pool, the set of drives would form a cube almost a kilometer wide (or about 781 meters). If we had enough drives to max out all \(2^{64}\) pools, they would occupy a volume six times greater than our sun.
Of course, we could pack data even denser, but we run the risk of creating a small black hole; it's really only at that point that the capacity limitations in ZFS become inconvenient. Until then, ZFS really is (at least in terms of its capacity limits) the final word in file systems.
Further Reading
If you're interested in reading more about ZFS, here are some additional resources.
Michael W Lucas and Allan Jude wrote two FreeBSD Mastery books called ZFS and Advanced ZFS that provide an excellent overview of the file system. Although presented in the context of FreeBSD, they're still very applicable to Linux-based ZFS systems. They're relatively short for technical books and very easy to read. You can find more information on the books at: www.zfsbook.com
The official OpenZFS docs are a very handy reference. The full set of man pages related to OpenZFS are also found here.
The OpenZFS YouTube channel has recordings of all presentations from past OepnZFS Dev Summits if you're interested in new feature development.
The github repo for the OpenZFS project can also be very useful as a more advanced reference. Even if you don't understand what is going on with the code, the comments provide some great insight that can't easily be found elsewhere. The repo can be found here.
The official TrueNAS documentation hub provides some great information on how ZFS is integrated into and managed by the OS.
The author of this guide has written several articles on ZFS:
- A usable capacity calculator and detailed guide on how ZFS uses your disk space
- A whitepaper on how different vdev layouts impact storage performance and reliability
- An guide to calculating and minimizing ZFS allocation overhead on RAIDZ pools
- A calculator and walkthrough for comparing pool and vdev failure